AWS Lambda Architecture Patterns
By Oleksandr Andrushchenko — Published on — Modified on
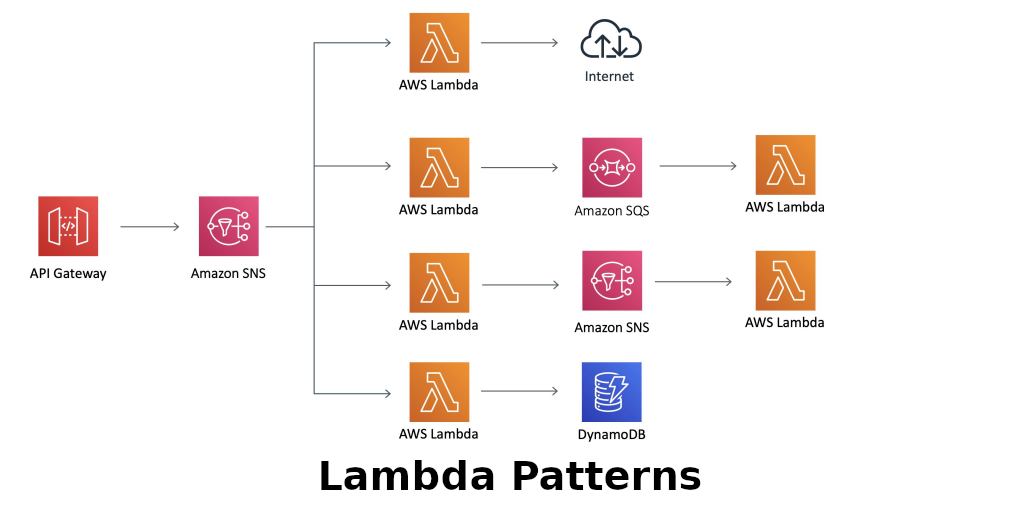
AWS Lambda is often introduced as a simple way to run code without managing servers. But in real production systems, Lambda is rarely used alone. It usually becomes part of a larger architecture with API Gateway, SQS, SNS, EventBridge, DynamoDB, S3, Step Functions, and other AWS services.
This article explains practical AWS Lambda architecture patterns that developers commonly use when building serverless APIs, background workers, event-driven systems, file processing pipelines, and workflow automation.
Table of Contents
- API Gateway + Lambda
- Lambda + SQS Worker
- Lambda + SNS Fan-Out
- Lambda + EventBridge
- Lambda + S3 File Processing
- Lambda + DynamoDB Streams
- Lambda + Step Functions
- Lambda Orchestrator Pattern
- Lambda Chaining
- Lambda + RDS
- Pattern Comparison
- Production Checklist
- Conclusion
API Gateway + Lambda
The most common Lambda architecture pattern is using API Gateway in front of Lambda. API Gateway receives an HTTP request, invokes Lambda, and returns the Lambda response to the client.
When to Use
- REST APIs for web or mobile applications
- Small backend services with simple request/response logic
- Internal tools and admin panels
- Webhook receivers from third-party systems
- Prototypes and MVP backends
Example Lambda Handler
import json
def lambda_handler(event, context):
user_id = event["pathParameters"]["userId"]
user = {
"id": user_id,
"name": "Demo User"
}
return {
"statusCode": 200,
"headers": {
"Content-Type": "application/json"
},
"body": json.dumps(user)
}Trade-Offs
| Benefit | Cost / Risk |
|---|---|
| Simple HTTP API architecture | Cold starts may affect latency |
| No server management | Request/response timeout limits matter |
| Easy integration with auth, throttling, and routing | Complex APIs can become harder to organize |
Rule of thumb: use API Gateway + Lambda for focused API endpoints, not for long-running request processing.
Lambda + SQS Worker
SQS is one of the best services to pair with Lambda. Instead of processing work immediately inside an API request, the application can place a message into a queue and let Lambda process it asynchronously.
When to Use
- Background jobs
- Email sending
- Report generation
- Image or document processing
- Retryable external API calls
- Load buffering before slow downstream systems
Example SQS Handler
def lambda_handler(event, context):
for record in event["Records"]:
message_body = record["body"]
print(f"Processing message: {message_body}")
return {
"processed": len(event["Records"])
}Why This Pattern Works Well
- SQS decouples producers from consumers.
- Messages can be retried automatically.
- Traffic spikes can be buffered.
- Failed messages can go to a dead-letter queue.
- Lambda concurrency can be controlled.
Important Warning
Do not assume every failed message should be retried forever. Some failures are temporary, but some are permanent. For example, invalid input will not become valid after ten retries.
Good design:
SQS Queue
-> Lambda Worker
-> Success: delete message
-> Temporary failure: retry
-> Permanent failure: send to DLQRule of thumb: use SQS between Lambda and unreliable or slow work.
Lambda + SNS Fan-Out
SNS is useful when one event should notify multiple subscribers. A single published message can trigger multiple Lambda functions, SQS queues, HTTP endpoints, or email notifications.
When to Use
- Fan-out notifications
- Simple event broadcasting
- Sending the same event to multiple systems
- Decoupling event producers from consumers
Example Scenario
When an order is created, several things may need to happen:
- Send confirmation email.
- Update analytics.
- Notify warehouse system.
- Start fraud checks.
SNS vs SQS
| Service | Main Purpose | Typical Pattern |
|---|---|---|
| SNS | Broadcast event to many subscribers | Fan-out |
| SQS | Store messages until workers process them | Queue worker |
| SNS + SQS | Broadcast events with durable buffering | Reliable fan-out |
Rule of thumb: use SNS when one event should be delivered to multiple independent consumers.
Lambda + EventBridge
EventBridge is a powerful event bus service for building event-driven architectures. It allows services to publish events and route them to targets based on rules.
When to Use
- Domain events such as
OrderCreated,UserRegistered, orPaymentFailed - Decoupled microservices
- Scheduled jobs
- SaaS integrations
- Event routing based on event type or payload fields
Example Event
{
"source": "app.orders",
"detail-type": "OrderCreated",
"detail": {
"orderId": "ord_123",
"customerId": "cus_456",
"amount": 120.50
}
}Example Rule Idea
{
"source": ["app.orders"],
"detail-type": ["OrderCreated"]
}This rule can route only OrderCreated events to a specific Lambda function.
EventBridge vs SNS
| Feature | SNS | EventBridge |
|---|---|---|
| Primary model | Pub/sub topic | Event bus with routing rules |
| Routing | Simple topic subscription | Advanced filtering by event pattern |
| Best for | Simple fan-out | Event-driven architecture |
| Common targets | Lambda, SQS, HTTP, email | Lambda, SQS, Step Functions, many AWS services |
Rule of thumb: use EventBridge when events represent business facts and need flexible routing.
Lambda + S3 File Processing
S3 event notifications can invoke Lambda when an object is created or deleted. This is a common pattern for file processing pipelines.
When to Use
- Image resizing
- Video metadata extraction
- CSV import pipelines
- PDF processing
- Antivirus scanning
- Data lake ingestion
Example S3 Handler
def lambda_handler(event, context):
for record in event["Records"]:
bucket = record["s3"]["bucket"]["name"]
key = record["s3"]["object"]["key"]
print(f"Processing file: s3://{bucket}/{key}")
return {
"processed": len(event["Records"])
}Avoid Recursive Triggers
Be careful when Lambda writes back to the same bucket that triggered it. If the output file also matches the trigger rule, the function can invoke itself repeatedly.
Bad:
uploads/image.jpg -> Lambda -> writes uploads/thumb.jpg -> triggers Lambda again
Better:
uploads/image.jpg -> Lambda -> writes thumbnails/thumb.jpgRule of thumb: use separate prefixes or buckets for input and output files.
Lambda + DynamoDB Streams
DynamoDB Streams capture changes to table items and can invoke Lambda when records are inserted, updated, or deleted.
When to Use
- Audit logs
- Search index synchronization
- Denormalized views
- Notifications after data changes
- Event-driven updates
Example Stream Handler
def lambda_handler(event, context):
for record in event["Records"]:
event_name = record["eventName"]
if event_name == "INSERT":
new_image = record["dynamodb"]["NewImage"]
print("New item inserted:", new_image)
if event_name == "MODIFY":
print("Item updated")
if event_name == "REMOVE":
print("Item deleted")
return {
"processed": len(event["Records"])
}Important Warning
Do not create infinite update loops. If Lambda reacts to a DynamoDB change and writes back to the same table, that write may trigger the stream again.
Bad:
DynamoDB update -> Stream -> Lambda -> update same item -> Stream -> Lambda again
Better:
DynamoDB update -> Stream -> Lambda -> write to another table / check processed flagRule of thumb: when writing back to the same table, use guard conditions to prevent repeated processing.
Lambda + Step Functions
AWS Step Functions are useful when a workflow has multiple steps, retries, branches, waits, or human-readable orchestration. Instead of putting all logic into one Lambda function, you model the workflow explicitly.
When to Use
- Multi-step workflows
- Order processing
- Document approval flows
- Long-running business processes
- Retry and compensation workflows
- ETL pipelines
Example Workflow
Validate Order
-> Reserve Inventory
-> Charge Payment
-> Send Confirmation
-> Update Order StatusWhy Step Functions Are Better Than One Huge Lambda
| One Huge Lambda | Step Functions |
|---|---|
| Workflow hidden inside code | Workflow visible as state machine |
| Manual retry logic | Built-in retries and error handling |
| Harder to resume from failure | Easier to track step-by-step execution |
| One timeout limit for everything | Workflow can span longer processes |
Rule of thumb: use Step Functions when the business process is more important than a single function call.
Lambda Orchestrator Pattern
In the Lambda orchestrator pattern, one Lambda function calls multiple services or other functions to complete a workflow.
When to Use
- Simple aggregation of multiple services
- Backend-for-Frontend APIs
- Small workflows that do not need Step Functions
- Combining multiple data sources into one response
Example Aggregation
def lambda_handler(event, context):
user = get_user(event["userId"])
orders = get_orders(event["userId"])
recommendations = get_recommendations(event["userId"])
return {
"user": user,
"orders": orders,
"recommendations": recommendations
}Warning
Do not turn the orchestrator into a giant distributed monolith. If the workflow grows, has many retries, needs branching, or must be observable step-by-step, move it to Step Functions.
| Use Lambda Orchestrator | Use Step Functions |
|---|---|
| Small aggregation logic | Multi-step workflow |
| Fast request/response | Long-running process |
| Simple error handling | Retries, branches, waits, compensation |
Lambda Chaining
Lambda chaining means one Lambda function directly invokes another Lambda function. This can work, but it is often overused.
Why Direct Chaining Can Be Risky
- Harder debugging: execution is spread across multiple functions.
- Hidden coupling: functions depend directly on each other.
- Retry confusion: failures can become difficult to reason about.
- Observability issues: tracing the full flow requires more effort.
Better Alternatives
| Instead of Direct Lambda Chaining | Use |
|---|---|
| Lambda A directly invokes Lambda B for background work | SQS |
| One event should notify many functions | SNS or EventBridge |
| Multi-step workflow | Step Functions |
| File processing after upload | S3 Event |
Rule of thumb: direct Lambda-to-Lambda invocation should be rare. Prefer queues, events, or workflows.
Lambda + RDS
Lambda can connect to relational databases such as Amazon RDS or Aurora, but this pattern needs careful design. Lambda can scale quickly, while relational databases have connection limits.
The Connection Problem
Traffic spike:
1,000 Lambda invocations
-> 1,000 database connections
-> RDS connection exhaustionBetter Design
- Reuse database clients across warm invocations.
- Use RDS Proxy to pool and manage connections.
- Limit Lambda concurrency to protect the database.
- Use SQS to buffer write-heavy workloads.
- Prefer DynamoDB for highly scalable key-value access patterns.
Connection Reuse Example
import os
import psycopg2
connection = None
def get_connection():
global connection
if connection is None or connection.closed:
connection = psycopg2.connect(
host=os.environ["DB_HOST"],
dbname=os.environ["DB_NAME"],
user=os.environ["DB_USER"],
password=os.environ["DB_PASSWORD"]
)
return connection
def lambda_handler(event, context):
conn = get_connection()
with conn.cursor() as cursor:
cursor.execute("SELECT now()")
result = cursor.fetchone()
return {
"databaseTime": str(result[0])
}Rule of thumb: Lambda + RDS can work well, but always design around connection management.
Pattern Comparison
| Pattern | Best For | Main Risk |
|---|---|---|
| API Gateway + Lambda | HTTP APIs and webhooks | Latency and timeout limits |
| Lambda + SQS | Background jobs and buffering | Poison messages and retry handling |
| Lambda + SNS | Fan-out notifications | Subscriber failure handling |
| Lambda + EventBridge | Event-driven architecture | Event schema management |
| Lambda + S3 | File processing | Recursive triggers |
| Lambda + DynamoDB Streams | Reacting to data changes | Infinite update loops |
| Lambda + Step Functions | Multi-step workflows | Workflow complexity and cost |
| Lambda + RDS | Relational data access | Database connection exhaustion |
Production Checklist
- Use API Gateway + Lambda for simple HTTP APIs and webhooks.
- Use SQS when work can be processed asynchronously.
- Use SNS when one event should notify multiple subscribers.
- Use EventBridge for domain events and flexible event routing.
- Use S3 events for file processing pipelines.
- Use DynamoDB Streams to react to table changes.
- Use Step Functions for multi-step business workflows.
- Avoid direct Lambda chaining unless the flow is very simple.
- Protect databases with RDS Proxy, concurrency limits, queues, or connection reuse.
- Configure dead-letter queues for async processing failures.
- Design idempotent functions because retries and duplicate events can happen.
- Use structured logs and tracing to debug distributed Lambda flows.
- Watch service quotas for concurrency, payload size, timeout, and downstream limits.
Conclusion
AWS Lambda architecture is not only about functions. Real serverless systems are built by combining Lambda with queues, topics, event buses, storage, databases, APIs, and workflow services.
The most important design decision is choosing the correct communication pattern. Use API Gateway for request/response APIs, SQS for background work, SNS for fan-out, EventBridge for domain events, S3 events for file processing, DynamoDB Streams for data changes, and Step Functions for workflows.
Key takeaway: good Lambda architecture is event-driven, decoupled, observable, retry-safe, and designed around downstream limits.


Comments (0)