Communication Protocols: Pros, Cons, and Use Cases
By Oleksandr Andrushchenko — Published on — Modified on
Modern distributed systems rely on communication protocols that define how services exchange data. As a software developer designing APIs, microservices, real-time systems, or event-driven platforms, choosing the correct protocol directly impacts latency, scalability, observability, cost, and developer productivity.
In this article, we will analyze the most widely used protocols in system design:
| Protocol | Built On | Model | Performance | Real-Time | Strengths | Weaknesses | Examples |
|---|---|---|---|---|---|---|---|
| HTTP / REST | TCP + TLS | Request / Response | Medium | No | Simple, ubiquitous, cacheable, stateless scaling | Over-fetching, chatty APIs | Public APIs, CRUD services |
| gRPC | HTTP/2 over TCP + TLS | RPC + Streaming | High | Streaming | High performance, strongly typed contracts | Binary tooling complexity | Internal microservices |
| WebSocket | HTTP Upgrade → TCP | Bidirectional Persistent | High | Yes | Low latency push, persistent connection | Connection scaling complexity | Live dashboards, chat, real-time apps |
| GraphQL | HTTP (usually) | Query-Based | Medium | No (Subscriptions possible) | Flexible data fetching, single endpoint | Query abuse risk, high schema complexity | Frontend data aggregation, flexible APIs |
| MQTT | TCP / TLS | Publish / Subscribe | High | Yes | Lightweight, efficient for unstable networks | Limited native security, broker dependency | IoT telemetry, device communication |
| AMQP | TCP | Message Queue | High | Async | Reliable delivery, routing flexibility | Broker management overhead | Reliable async workflows |
| Kafka Protocol | TCP | Event Streaming (Log) | Very High | Async | High throughput, replayable events | Operational complexity | Event-driven architectures |
Table of Contents
- HTTP / REST
- gRPC
- WebSocket
- GraphQL
- MQTT
- AMQP
- Kafka Protocol
- Protocol Selection Cheatsheet
- Final Thoughts
1. HTTP / REST
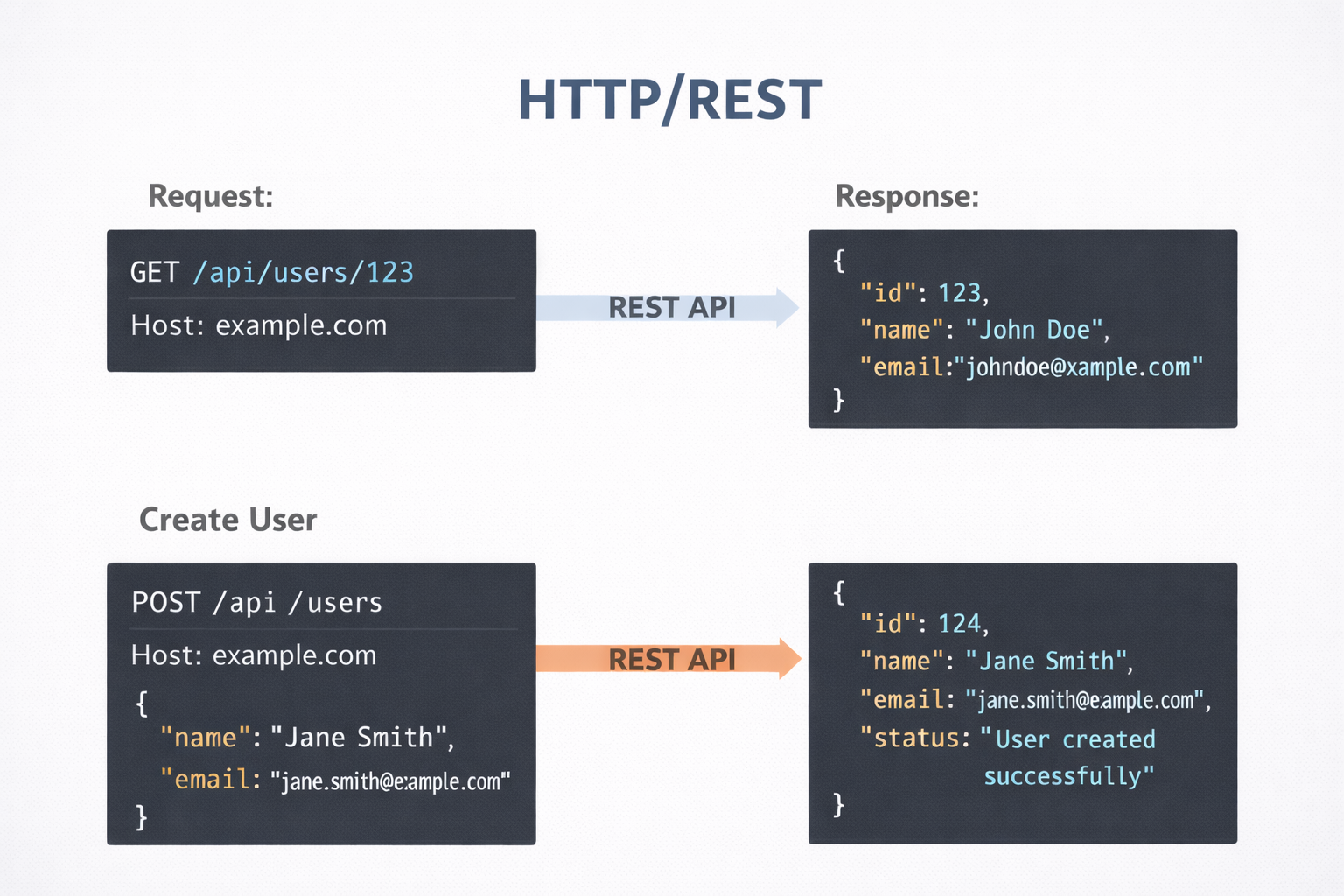
HTTP is the foundation of the web. REST (Representational State Transfer) is an architectural style built on top of HTTP using verbs like GET, POST, PUT, and DELETE.
Advantages
- Universal support
- Easy debugging
- Human-readable JSON
- Cache support
- Stateless design
Disadvantages
- Over-fetching and under-fetching
- High latency in chatty services
- No built-in schema enforcement
- Text-based overhead
When to Use / Real-World Use Cases
- Public APIs and client-server communication with simple request/response models (e.g., mobile apps, web apps, third-party integrations)
- CRUD-based applications and resource management systems (e.g., user management, product catalogs, content platforms)
- Systems requiring strong caching support and HTTP ecosystem tooling (e.g., CDN caching, browser caching, API gateways)
- External integrations and public-facing services (e.g., payment APIs, SaaS APIs, partner integrations)
- Simple architectures where transparency, simplicity, and wide adoption are priorities (e.g., small to medium backend services)
Example
Server (get/create user API, Node.js Express):
const express = require('express');
const app = express();
app.use(express.json());
// Get user by ID
app.get('/users/:id', (req, res) => {
res.json({ id: req.params.id, name: "John" });
});
// Create new user
app.post('/users', (req, res) => {
res.status(201).json({ id: 1, ...req.body });
});
app.listen(3000);Client (get/create user API calls, JavaScript):
// Get user by ID
async function getUser(id) {
const response = await fetch(`http://localhost:3000/users/${id}`);
if (!response.ok) {
throw new Error("Failed to fetch user");
}
return await response.json();
}
getUser(1).then(console.log).catch(console.error);
// Create new user
async function createUser(userData) {
const response = await fetch("http://localhost:3000/users", {
method: "POST",
headers: {
"Content-Type": "application/json",
},
body: JSON.stringify(userData),
});
if (!response.ok) {
throw new Error("Failed to create user");
}
return await response.json();
}
createUser({ name: "Alice" }).then(console.log).catch(console.error);Key takeaway: HTTP / REST is still the most practical default for many public APIs because it is simple, widely supported, easy to debug, and works well with existing web infrastructure.
2. gRPC
gRPC is a high-performance RPC framework built on HTTP/2 and Protocol Buffers.
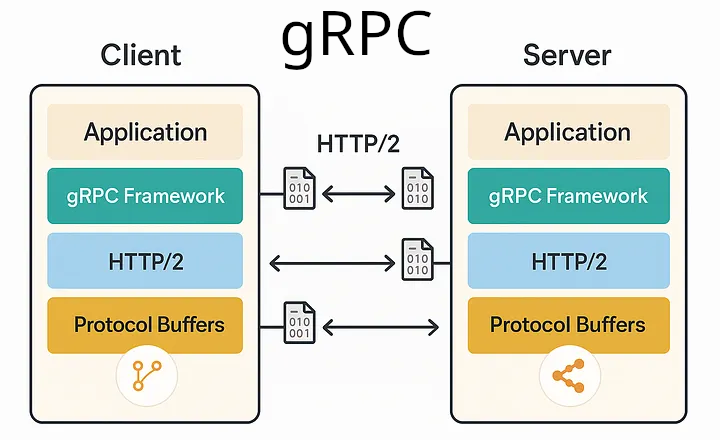
Key Characteristics
- Binary serialization (Protobuf)
- HTTP/2 multiplexing
- Strongly typed contracts
- Streaming support
Advantages
- High performance
- Low latency
- Code generation
- Streaming support
Disadvantages
- Harder debugging
- Binary protocol is not human-readable
- Less browser-native support
When to Use / Real-World Use Cases
- High-performance internal microservices communication (e.g., auth service → user service → billing service)
- Backend-to-backend RPC communication with strict contracts (e.g., payment processing, order validation)
- Systems requiring low-latency and high-throughput communication (e.g., trading systems, real-time data processing)
- Polyglot environments with strongly typed service definitions (e.g., services written in Go, Java, Python, Node)
- Streaming data between services or from client to server (e.g., live log streaming, data ingestion pipelines)
Example
Protobuf definition:
syntax = "proto3";
service UserService {
rpc GetUser (UserRequest) returns (UserResponse);
}
message UserRequest {
int32 id = 1;
}
message UserResponse {
int32 id = 1;
string name = 2;
}Server (get user service, Node.js):
const grpc = require("@grpc/grpc-js");
const protoLoader = require("@grpc/proto-loader");
const PROTO_PATH = "./user.proto";
const packageDefinition = protoLoader.loadSync(PROTO_PATH);
const proto = grpc.loadPackageDefinition(packageDefinition);
const userService = {
GetUser: (call, callback) => {
const userId = call.request.id;
// Example fake DB
const user = {
id: userId,
name: "John Doe",
};
callback(null, user);
},
};
const server = new grpc.Server();
server.addService(proto.UserService.service, userService);
server.bindAsync("0.0.0.0:50051", grpc.ServerCredentials.createInsecure(), () => {
console.log("🚀 gRPC server running on port 50051");
server.start();
});Client (get user service, JavaScript):
const grpc = require("@grpc/grpc-js");
const protoLoader = require("@grpc/proto-loader");
const PROTO_PATH = "./user.proto";
const packageDefinition = protoLoader.loadSync(PROTO_PATH);
const proto = grpc.loadPackageDefinition(packageDefinition);
// Create client
const client = new proto.UserService(
"localhost:50051",
grpc.credentials.createInsecure()
);
// Call RPC
client.GetUser({id: 1}, (error, response) => {
if (error) {
console.error("Error:", error);
return;
}
console.log("User received from gRPC:", response);
});Key takeaway: gRPC is usually a strong choice for internal service-to-service communication where performance, contracts, and streaming matter more than human-readable payloads.
3. WebSocket
WebSocket enables full-duplex persistent connections between client and server.
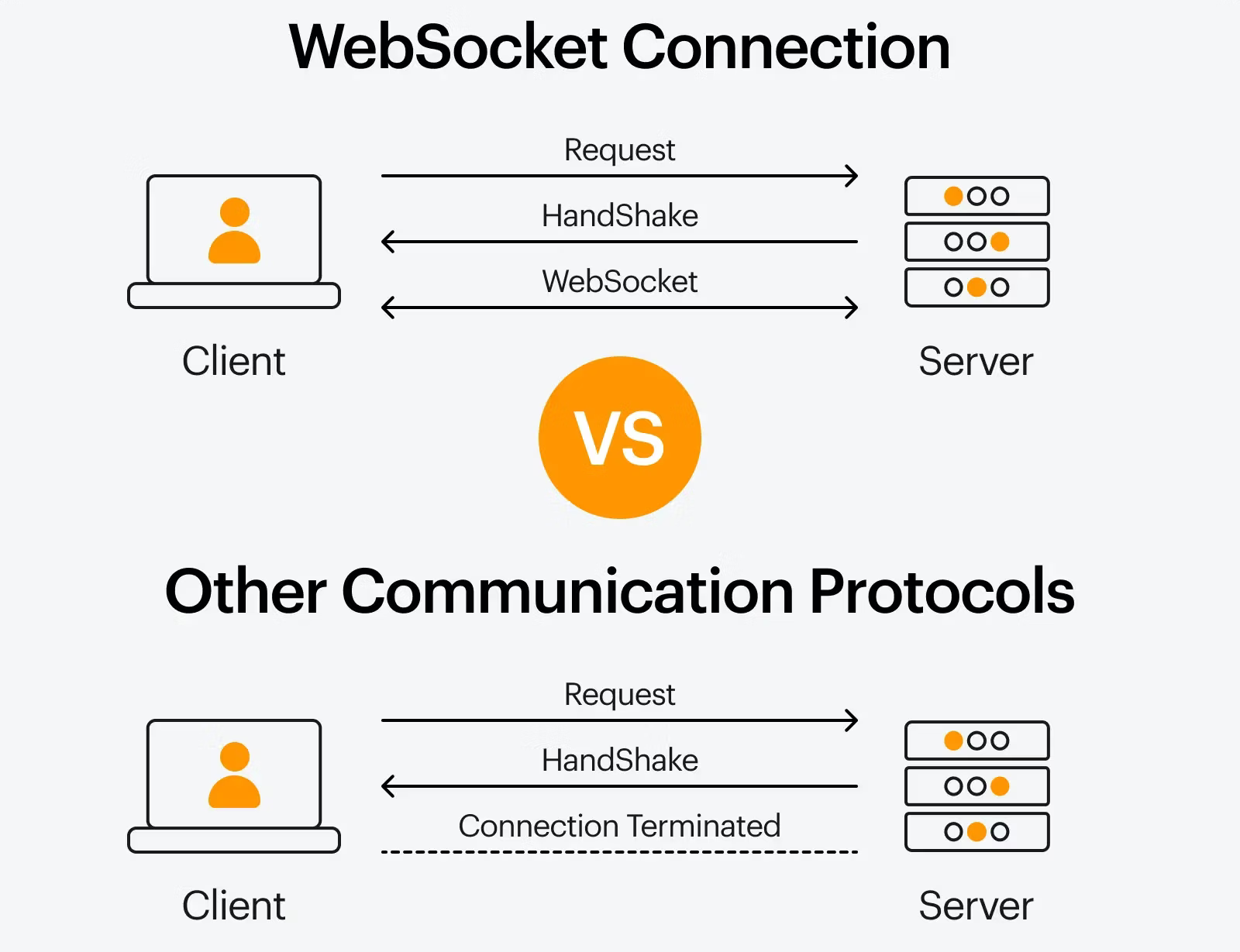
Advantages
- Real-time communication
- Low overhead after handshake
- Bidirectional messaging
Disadvantages
- No built-in reconnection logic
- Harder horizontal scaling
- Requires sticky sessions or pub/sub backend
When to Use / Real-World Use Cases
- Real-time communication between client and server (e.g., chat applications, live support systems)
- Live dashboards and monitoring tools (e.g., system metrics, stock prices, analytics updates)
- Collaborative applications requiring instant updates (e.g., shared editing, whiteboards, multiplayer apps)
- Applications requiring server-to-client push notifications (e.g., alerts, status updates, activity feeds)
- High-frequency data streaming with persistent connections (e.g., IoT live monitoring, gaming events)
Example
Server (get/create user, Node.js):
const WebSocket = require("ws");
const wss = new WebSocket.Server({port: 8080});
let users = [{id: 1, name: "John"}];
wss.on("connection", (ws) => {
ws.on("message", (msg) => {
const data = JSON.parse(msg);
if (data.action === "getUser") {
const user = users.find(u => u.id === data.id);
ws.send(JSON.stringify(user || {}));
}
if (data.action === "createUser") {
const newUser = {
id: users.length + 1,
name: data.name,
};
users.push(newUser);
ws.send(JSON.stringify(newUser));
}
});
});
console.log("WebSocket server running on ws://localhost:8080");Client (get/create user, JavaScript):
const ws = new WebSocket("ws://localhost:8080");
ws.onopen = () => {
ws.send(JSON.stringify({action: "getUser", id: 1}));
ws.send(JSON.stringify({action: "createUser", name: "Alice"}));
};
ws.onmessage = (event) => {
console.log("Response:", event.data);
};Key takeaway: WebSocket is useful when the server must push updates to the client instantly, but persistent connections add scaling and reliability challenges.
4. GraphQL
GraphQL is a query language for APIs allowing clients to request exactly the data they need.
Advantages
- Eliminates over-fetching
- Strong schema
- Single endpoint
Disadvantages
- Complex caching
- N+1 query problem
- More complex backend
When to Use / Real-World Use Cases
- Frontend-driven applications requiring flexible data fetching (e.g., React/SPA apps, mobile apps)
- Applications with complex or nested data relationships (e.g., user → orders → products → reviews)
- Backend-for-Frontend layer for aggregating multiple services (e.g., combining user + billing + profile data)
- APIs where clients need control over response fields to avoid over-fetching (e.g., dashboards, analytics tools)
- Public or internal APIs requiring schema-based contracts and introspection (e.g., developer platforms, ecosystem APIs)
Example
Server (get/create user API, Node.js Apollo):
const {ApolloServer, gql} = require("apollo-server");
let users = [{id: 1, name: "John"}];
// Schema (Types + Operations)
const typeDefs = gql`
type User {
id: Int!
name: String!
}
type Query {
getUser(id: Int!): User
}
type Mutation {
createUser(name: String!): User
}
`;
// Resolvers (Business Logic)
const resolvers = {
Query: {
getUser: (_, {id}) => {
return users.find(user => user.id === id);
},
},
Mutation: {
createUser: (_, {name}) => {
const newUser = {
id: users.length + 1,
name,
};
users.push(newUser);
return newUser;
},
},
};
const server = new ApolloServer({typeDefs, resolvers});
server.listen({port: 4000}).then(({url}) => {
console.log(`🚀 GraphQL server running at ${url}`);
});Client (get/create user API calls, JavaScript):
async function req(query, variables = {}) {
const response = await fetch("http://localhost:4000/", {
method: "POST",
headers: {
"Content-Type": "application/json",
},
body: JSON.stringify({
query,
variables,
}),
});
const result = await response.json();
return result.data;
}
// Get User
req(
`
query GetUser($id: Int!) {
getUser(id: $id) {
id
name
}
}
`,
{id: 1}
).then(console.log);
// Create User
req(
`
mutation CreateUser($name: String!) {
createUser(name: $name) {
id
name
}
}
`,
{name: "Alice"}
).then(console.log);Key takeaway: GraphQL is powerful when clients need flexible data fetching, but backend teams must control query complexity, caching, authorization, and N+1 problems carefully.
5. MQTT
MQTT is a lightweight publish/subscribe protocol designed for IoT.
Characteristics
- Low bandwidth usage
- Pub/Sub model
- QoS levels (0, 1, 2)
Advantages
- Very lightweight
- Battery-efficient
- Reliable delivery options
Disadvantages
- Not ideal for complex APIs
- Limited message size
When to Use / Real-World Use Cases
- IoT device communication with lightweight messaging (e.g., sensors, smart home devices, industrial equipment)
- Real-time telemetry data collection (e.g., temperature monitoring, GPS tracking, device metrics)
- Unstable or low-bandwidth network environments (e.g., remote devices, mobile-connected hardware)
- Publish/subscribe systems for event distribution (e.g., device status updates, live alerts)
- Systems requiring persistent lightweight connections with QoS guarantees (e.g., remote device control, fleet management)
Example
Publisher (Python, sends temperature data):
import paho.mqtt.client as mqtt
import json
import random
import time
BROKER = "localhost"
PORT = 1883
TOPIC = "devices/temperature"
client = mqtt.Client()
client.connect(BROKER, PORT)
print("✅ Publisher connected to broker")
while True:
message = {
"deviceId": 1,
"temperature": random.randint(10, 40),
"timestamp": int(time.time())
}
client.publish(TOPIC, json.dumps(message))
print("📤 Published:", message)
time.sleep(2)Subscriber (Python):
import paho.mqtt.client as mqtt
import json
BROKER = "localhost"
PORT = 1883
TOPIC = "devices/temperature"
def on_connect(client, userdata, flags, rc):
print("✅ Subscriber connected")
client.subscribe(TOPIC)
print(f"📡 Subscribed to {TOPIC}")
def on_message(client, userdata, msg):
data = json.loads(msg.payload.decode())
print("📩 Topic:", msg.topic)
print("📊 Received:", data)
client = mqtt.Client()
client.on_connect = on_connect
client.on_message = on_message
client.connect(BROKER, PORT)
client.loop_forever()Key takeaway: MQTT is a strong fit for IoT, telemetry, and low-bandwidth device communication, but it is not a general-purpose replacement for HTTP APIs.
6. AMQP
AMQP is an advanced message queuing protocol used by systems like RabbitMQ.
Advantages
- Reliable messaging
- Flexible routing
- Durability
Disadvantages
- Operational complexity
- Broker dependency
When to Use / Real-World Use Cases
- Reliable async communication with guaranteed message delivery (e.g., order events, payment confirmations)
- Background job processing and task queues (e.g., image processing, report generation, email sending)
- Complex service-to-service routing via message broker (e.g., microservices event distribution)
- Order, payment, and transaction processing systems (e.g., e-commerce checkout pipeline)
- Event-driven architectures requiring durability and retries (e.g., audit logging, analytics ingestion)
- Enterprise system integration and workflow automation (e.g., legacy system integration, ERP communication)
Example
Publisher (Python, order service):
import pika
import json
connection = pika.BlockingConnection(
pika.ConnectionParameters("localhost")
)
channel = connection.channel()
# Create queue
channel.queue_declare(queue="orders")
order = {
"orderId": 1,
"amount": 250,
"status": "CREATED"
}
channel.basic_publish(
exchange="",
routing_key="orders",
body=json.dumps(order)
)
print("📤 Order published:", order)
connection.close()Consumer (Python, payment service):
import pika
import json
def callback(ch, method, properties, body):
order = json.loads(body)
print("📩 Received order:", order)
# Simulate processing
print("💳 Processing payment...")
# Acknowledge message
ch.basic_ack(delivery_tag=method.delivery_tag)
connection = pika.BlockingConnection(
pika.ConnectionParameters("localhost")
)
channel = connection.channel()
channel.queue_declare(queue="orders")
channel.basic_consume(
queue="orders",
on_message_callback=callback,
auto_ack=False
)
print("✅ Waiting for messages...")
channel.start_consuming()Key takeaway: AMQP is useful when you need reliable queues, acknowledgements, retries, routing, and broker-controlled message delivery.
7. Kafka Protocol
Apache Kafka protocol is optimized for distributed streaming and event sourcing.
Advantages
- High throughput
- Durable log storage
- Event replay
Disadvantages
- Complex operations
- Eventual consistency challenges
When to Use / Real-World Use Cases
- High-throughput event streaming systems (e.g., user activity tracking, clickstream analytics)
- Event-driven microservices architectures (e.g., order events, inventory updates, payment events)
- Real-time data pipelines and stream processing (e.g., log aggregation, metrics ingestion, fraud detection)
- System decoupling through asynchronous event communication (e.g., service-to-service event publishing)
- Data integration between distributed systems with replay capability (e.g., audit logs, data replication, CDC)
Example
Producer (Python, order service):
from kafka import KafkaProducer
import json
import time
producer = KafkaProducer(
bootstrap_servers="localhost:9092",
value_serializer=lambda v: json.dumps(v).encode("utf-8")
)
topic = "orders"
order_id = 1
while True:
event = {
"orderId": order_id,
"amount": 100 + order_id,
"status": "CREATED"
}
producer.send(topic, event)
print("📤 Published:", event)
order_id += 1
time.sleep(2)Consumer (Python, analytics or payment service):
from kafka import KafkaConsumer
import json
consumer = KafkaConsumer(
"orders",
bootstrap_servers="localhost:9092",
auto_offset_reset="earliest",
enable_auto_commit=True,
value_deserializer=lambda x: json.loads(x.decode("utf-8"))
)
print("✅ Waiting for messages...")
for message in consumer:
event = message.value
print("📩 Received:", event)
# Simulate processing
print("⚙ Processing order:", event["orderId"])Key takeaway: Kafka is best when you need high-throughput event streams, durable logs, replayable events, and multiple independent consumers.
Protocol Selection Cheatsheet
| If You Need | Consider | Why |
|---|---|---|
| Simple public API | HTTP / REST | Easy to use, debug, document, and integrate |
| Fast internal service calls | gRPC | Strong contracts, binary format, HTTP/2 multiplexing |
| Real-time browser updates | WebSocket | Persistent bidirectional connection |
| Flexible frontend data fetching | GraphQL | Client controls response shape |
| IoT device messaging | MQTT | Lightweight pub/sub protocol |
| Reliable task queues | AMQP | Acknowledgements, routing, retries, durability |
| High-throughput event streaming | Kafka Protocol | Durable log, replay, consumer groups |
Final Thoughts
There is no universally “best” protocol. The correct choice depends on:
- Latency requirements
- Data size
- Traffic patterns
- Consistency model
- Operational expertise
The best architects understand trade-offs, not just technologies.

Comments (0)