AWS Lambda Explained: A Beginner-Friendly Introduction
By Oleksandr Andrushchenko — Published on — Modified on

AWS Lambda is a serverless compute service that allows you to run code without creating or managing servers. Instead of provisioning EC2 instances, installing runtimes, configuring scaling rules, and patching operating systems, you write a function and configure when it should run.
Lambda is commonly used for REST APIs, background jobs, file processing, scheduled tasks, queue workers, and event-driven systems. This article explains the core ideas with practical examples, code snippets, tables, and simple architecture diagrams.
Table of Contents
- What Is AWS Lambda?
- How AWS Lambda Works
- Writing Your First Lambda Function
- Common AWS Lambda Triggers
- Lambda Execution Lifecycle
- Scaling and Concurrency
- AWS Lambda Pricing
- Advantages and Limitations
- AWS Lambda Best Practices
- Real-World Examples
- Conclusion
What Is AWS Lambda?
AWS Lambda is a managed compute service where the main deployment unit is a function. You upload code, configure a trigger, and AWS runs that code when the trigger fires.
A Lambda function can handle an HTTP request, process an uploaded file, consume queue messages, react to database changes, or run on a schedule.
What Does Serverless Mean?
Serverless does not mean there are no servers. It means you do not manage those servers directly. AWS handles the infrastructure, runtime, scaling, availability, and much of the operational work.
- You write code.
- AWS runs the code.
- AWS scales the infrastructure.
- You pay based on usage.
Function as a Service
Lambda is often described as Function as a Service, or FaaS. Instead of deploying a full server application, you deploy focused functions that run when needed.
def lambda_handler(event, context):
return "Hello from Lambda"Lambda vs Traditional Server
| Traditional Server | AWS Lambda |
|---|---|
| Application runs continuously | Function runs when invoked |
| You manage server capacity | AWS scales automatically |
| You patch and maintain the OS | AWS manages the infrastructure |
| You pay for uptime | You pay mostly for requests and duration |
| Good for long-running services | Good for short event-driven tasks |
How AWS Lambda Works
Lambda is built around events. An event happens, Lambda receives input, your handler function runs, and the function either returns a response or performs a side effect.
Basic Lambda Flow
- An event happens in AWS or an external system.
- A trigger invokes the Lambda function.
- Lambda prepares an execution environment.
- Your handler receives the event.
- Your code processes the event.
- The function returns a result or writes data somewhere.
The Event Object
The event object contains data from the service that triggered the function. Its structure depends on the trigger.
{
"httpMethod": "GET",
"path": "/users/42",
"queryStringParameters": {
"includeOrders": "true"
}
}def lambda_handler(event, context):
path = event["path"]
return {
"statusCode": 200,
"body": f"Requested path: {path}"
}The Context Object
The context object contains runtime information about the function invocation, such as request ID, function name, memory limit, and remaining execution time.
| Object | Purpose |
|---|---|
event |
Input data from API Gateway, S3, SQS, EventBridge, or another trigger |
context |
Runtime metadata about the current Lambda invocation |
return |
Output returned to the caller or integration |
Writing Your First Lambda Function
A basic Lambda function usually has a handler. The handler is the entry point AWS calls when your function is invoked.
Python Example
import json
def lambda_handler(event, context):
name = event.get("name", "developer")
response = {
"message": f"Hello, {name}!"
}
return {
"statusCode": 200,
"body": json.dumps(response)
}Example input:
{
"name": "Alex"
}Example output:
{
"statusCode": 200,
"body": "{\"message\": \"Hello, Alex!\"}"
}Returning an API Response
When Lambda is used behind API Gateway, it often returns an object with statusCode, headers, and body.
import json
def lambda_handler(event, context):
user = {
"id": 42,
"name": "Alex"
}
return {
"statusCode": 200,
"headers": {
"Content-Type": "application/json"
},
"body": json.dumps(user)
}Using Environment Variables
Environment variables are useful for configuration values such as table names, bucket names, feature flags, and API endpoints.
import os
TABLE_NAME = os.environ["TABLE_NAME"]
def lambda_handler(event, context):
return {
"statusCode": 200,
"body": f"Using table: {TABLE_NAME}"
}Rule of thumb: do not hardcode environment-specific values directly in the function code.
Common AWS Lambda Triggers
Lambda functions usually run because another service invokes them. This is what makes Lambda useful for event-driven architecture.
| Trigger | Use Case | Example |
|---|---|---|
| API Gateway | HTTP APIs | GET /users/42 invokes Lambda |
| S3 | File processing | Upload image, create thumbnail |
| SQS | Queue workers | Process background jobs |
| SNS | Pub/sub notifications | Notify multiple subscribers |
| EventBridge | Event routing and schedules | Run scheduled cleanup |
| DynamoDB Streams | React to database changes | Process newly inserted records |
API Gateway
API Gateway can route HTTP requests to Lambda. This is a common way to build serverless REST APIs.
import json
def lambda_handler(event, context):
user_id = event["pathParameters"]["userId"]
user = {
"id": user_id,
"name": "Demo User"
}
return {
"statusCode": 200,
"body": json.dumps(user)
}S3 Events
Amazon S3 can invoke Lambda when a file is uploaded, deleted, or changed. This is useful for image processing, file validation, metadata extraction, and import pipelines.
def lambda_handler(event, context):
for record in event["Records"]:
bucket = record["s3"]["bucket"]["name"]
key = record["s3"]["object"]["key"]
print(f"New file uploaded: s3://{bucket}/{key}")
return {
"processed": len(event["Records"])
}SQS and SNS
Amazon SQS is commonly used for queue-based background jobs. Amazon SNS is commonly used for pub/sub notifications.
def lambda_handler(event, context):
for record in event["Records"]:
message = record["body"]
print(f"Processing message: {message}")
return {
"processed": len(event["Records"])
}| Service | Best For |
|---|---|
| SQS | Reliable queue processing and background workers |
| SNS | Fan-out notifications to multiple subscribers |
EventBridge
EventBridge can route events from AWS services, custom applications, schedules, and SaaS integrations to Lambda functions.
EventBridge is useful when you want to decouple systems. One service publishes an event, and another service reacts to it without direct dependency between them.
DynamoDB Streams
DynamoDB Streams can invoke Lambda when records in a DynamoDB table are inserted, updated, or deleted.
- Send notification after a new record is created.
- Update a search index after data changes.
- Write audit logs.
- Synchronize data into another system.
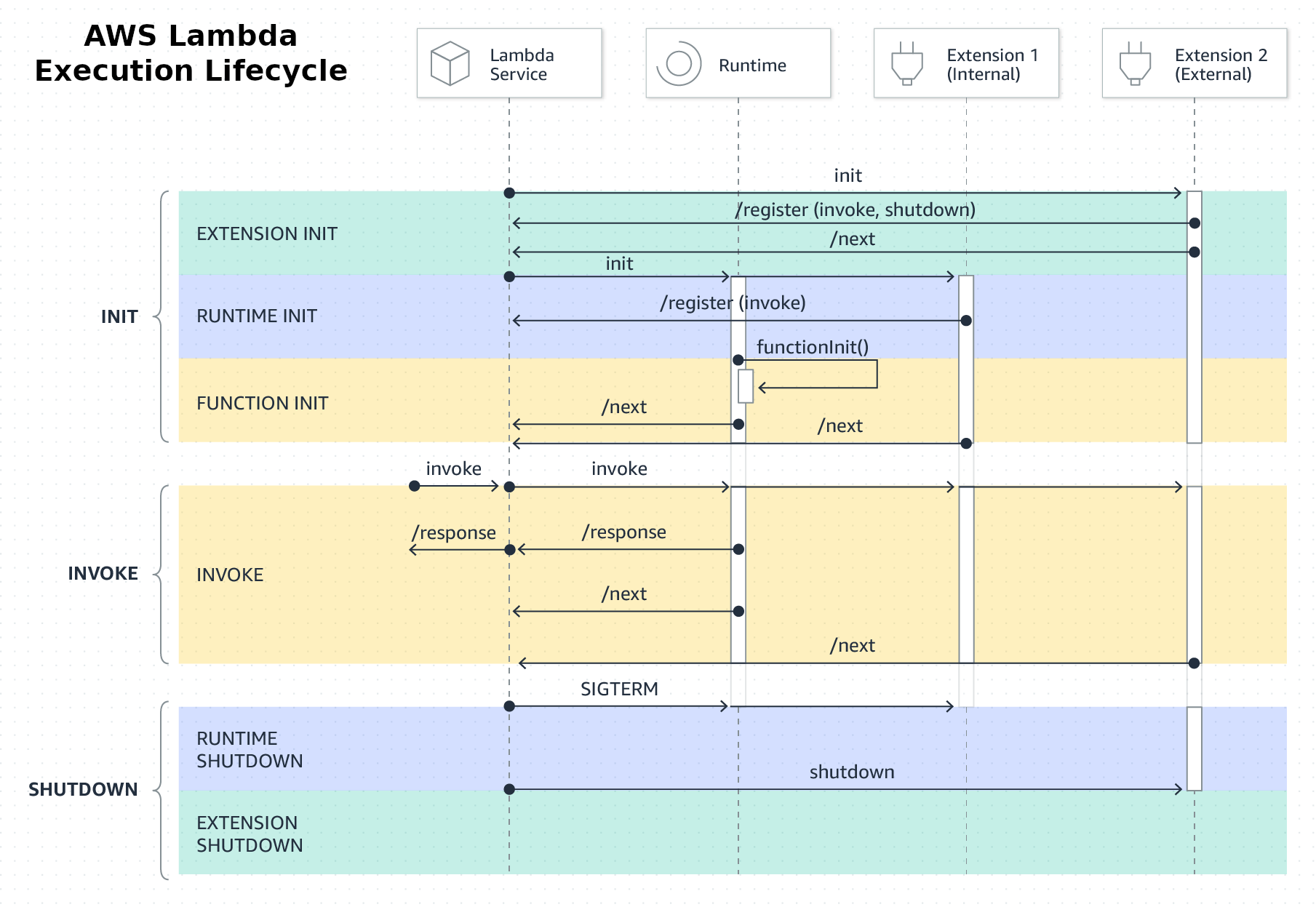
Lambda Execution Lifecycle
Lambda functions are not always started from zero. AWS can create an execution environment and reuse it for future invocations.
Cold Starts
A cold start happens when Lambda needs to create a new execution environment before running your function. This can add latency because AWS needs to prepare the runtime and initialize your code.
Warm Starts
A warm start happens when Lambda reuses an existing execution environment. Warm starts are usually faster because some initialization work has already happened.
| Type | What Happens | Typical Result |
|---|---|---|
| Cold start | New environment is created | Slower invocation |
| Warm start | Existing environment is reused | Faster invocation |
Global Variable Reuse
Code outside the handler runs during initialization and may be reused during warm invocations. This is useful for SDK clients, configuration loading, and expensive setup.
import boto3
s3_client = boto3.client("s3")
def lambda_handler(event, context):
buckets = s3_client.list_buckets()
return {
"bucketCount": len(buckets["Buckets"])
}Important: reuse global clients, but do not store request-specific user state in global variables.
Scaling and Concurrency
Concurrency means the number of Lambda invocations running at the same time. If 100 requests are being processed at the same moment, the function has about 100 concurrent executions.
| Feature | Purpose |
|---|---|
| Default concurrency | Lambda scales automatically within account and regional quotas. |
| Reserved concurrency | Reserves capacity for one function and can also limit its maximum concurrency. |
| Provisioned concurrency | Keeps environments initialized to reduce cold start latency. |
Important: Lambda can scale quickly, but downstream systems may not. A database, external API, or legacy service can become the bottleneck.
Bad design:
1,000 Lambda executions -> 1,000 direct database connections
Better design:
1,000 Lambda executions -> SQS / RDS Proxy / throttling / connection reuseAWS Lambda Pricing
Lambda pricing is based mainly on number of requests and execution duration. Memory size also matters because compute cost is related to configured memory and execution time.
| Pricing Factor | Meaning |
|---|---|
| Requests | How many times the function is invoked |
| Duration | How long the function runs |
| Memory | How much memory is configured for the function |
| Architecture | x86 or Arm can affect price and performance |
| Provisioned concurrency | Additional cost for keeping environments ready |
Total cost depends on:
number of invocations
× execution duration
× configured memory
+ optional features such as provisioned concurrencyRule of thumb: Lambda is often cost-efficient for irregular, short-running, event-driven workloads. For constantly running high-throughput workloads, containers or servers may sometimes be cheaper.
Advantages and Limitations
Lambda is powerful, but it is not a universal replacement for every backend architecture.
| Advantages | Limitations |
|---|---|
| Less infrastructure management | Maximum execution time limit |
| Automatic scaling | Cold starts can add latency |
| Good AWS service integrations | Stateless execution model |
| Useful pay-per-use model | Debugging distributed flows can be harder |
| Good for event-driven systems | Service quotas and payload limits matter |
Lambda vs Containers
| Use Lambda When | Use Containers When |
|---|---|
| You have short event-driven tasks | You need long-running services |
| You want minimal infrastructure management | You need more runtime and networking control |
| Traffic is irregular or spiky | Traffic is constant and predictable |
| Function-level scaling is enough | You need full application-level control |
AWS Lambda Best Practices
Even beginner Lambda projects should follow a few practical rules. These habits prevent many production problems later.
- Keep functions small and focused. A function should usually do one clear job.
- Use environment variables. Do not hardcode table names, bucket names, or endpoints.
- Write idempotent handlers. The same event may be retried or delivered more than once.
- Reuse SDK clients. Initialize clients outside the handler when possible.
- Use structured logging. Logs should help you debug real production issues.
- Configure timeouts intentionally. Do not leave default values without thinking.
- Grant least-privilege IAM permissions. Give the function only what it needs.
- Protect downstream systems. Use queues, throttling, reserved concurrency, or RDS Proxy when needed.
Idempotency Example
Idempotency means the same event can be processed more than once without causing incorrect behavior.
def process_order(order_id):
if order_already_processed(order_id):
return "already_processed"
charge_customer(order_id)
mark_order_as_processed(order_id)
return "processed"Least-Privilege IAM Example
If a function only needs to read files from one S3 bucket, do not give it full AWS admin access.
{
"Effect": "Allow",
"Action": [
"s3:GetObject"
],
"Resource": [
"arn:aws:s3:::example-bucket/*"
]
}Real-World Examples
REST API Backend
- User sends an HTTP request.
- API Gateway invokes Lambda.
- Lambda validates input and reads or writes data.
- Lambda returns an HTTP response.
Image Processing
- User uploads an image to S3.
- S3 sends an event to Lambda.
- Lambda downloads the file.
- Lambda creates a thumbnail or extracts metadata.
Queue Worker
- Application sends a job to SQS.
- Lambda reads messages from the queue.
- Lambda processes each message.
- Failed messages can be retried or moved to a dead-letter queue.
Scheduled Job
- Run cleanup every night.
- Generate reports every morning.
- Synchronize data every hour.
- Check system health periodically.
Conclusion
AWS Lambda is a practical way to run code without managing servers. It works especially well for APIs, file processing, background jobs, scheduled tasks, queue workers, and event-driven architectures.
The core idea is simple: an event happens, Lambda runs your function, and your function performs a task. Behind that simple model, there are important concepts such as cold starts, warm starts, concurrency, retries, IAM permissions, logging, and downstream limits.
Key takeaway: Lambda is best for short-running, focused, event-driven workloads. It can reduce operational overhead, but it still requires good engineering around reliability, observability, permissions, and system design.
Next Articles to Read
This article covered the fundamentals of AWS Lambda. As you start building production serverless applications, the following topics are worth exploring in more depth:

Comments (1)