SQL Databases: Overview, Concepts, and Use Cases
By Oleksandr Andrushchenko — Published on — Modified on

SQL databases (also known as relational databases) are systems designed to store, organize, and query structured data using a predefined schema. They are built around the relational model, where data is stored in tables and relationships between entities are explicitly defined.
For decades, SQL databases have been the foundation of most applications — from small startups to large-scale enterprise systems. Despite the rise of NoSQL solutions, SQL remains the default choice for many system design problems due to its consistency, flexibility, and powerful querying capabilities.
Core Concepts of SQL Databases
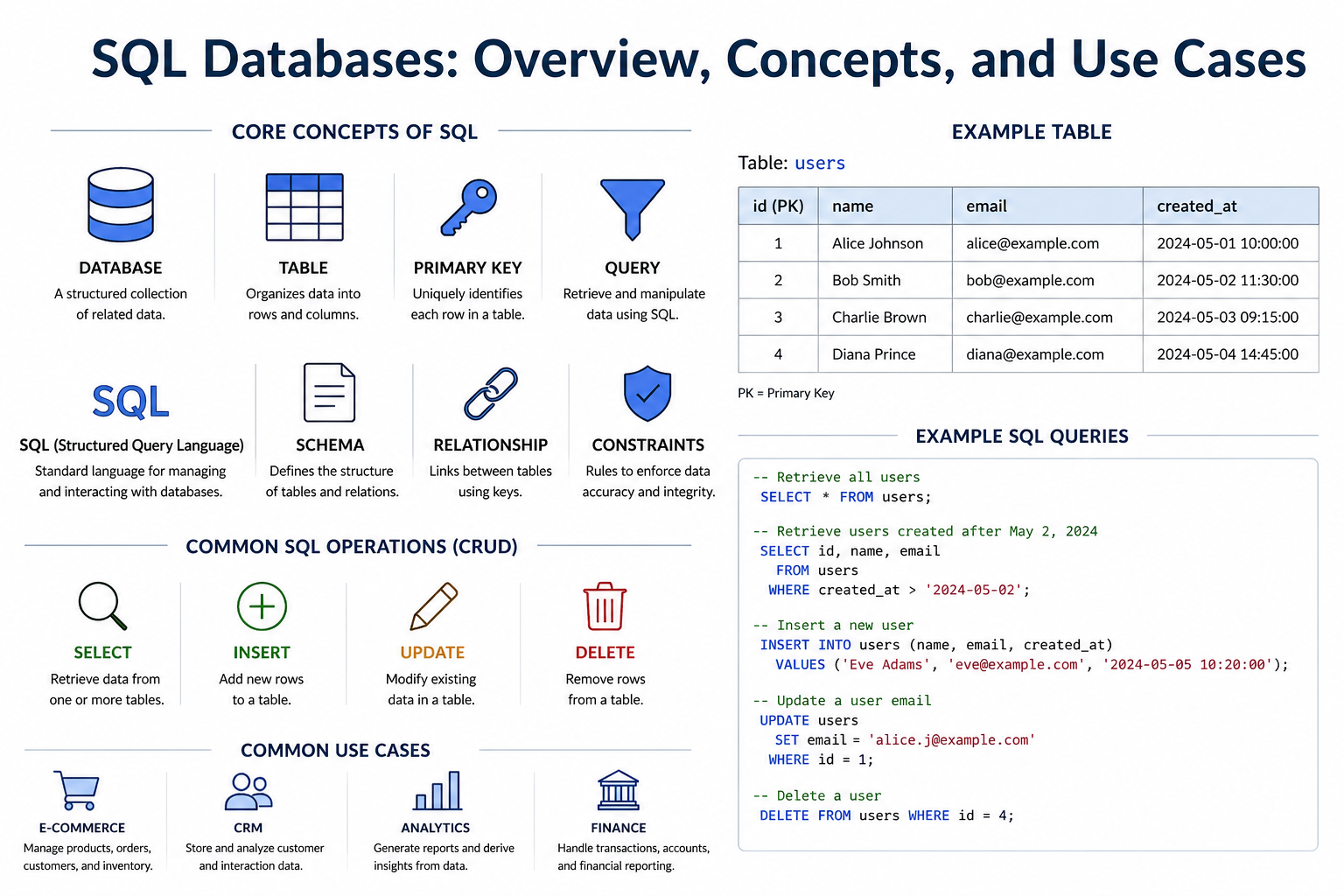
Understanding SQL databases starts with a few fundamental concepts that define how data is structured, stored, and executed. SQL databases are based on the relational model, where data is split into multiple related tables instead of being stored in a single structure.
- Tables: Data is stored in rows and columns
- Rows: Individual records (e.g., user or order)
- Columns: Attributes of the data (e.g., name, email)
- Primary Key: Unique identifier for each row
- Foreign Key: Reference between tables
Example: Users and Orders Tables
TABLE: users
+----+--------+----------------------+
| id | name | email | <--- columns (attributes)
+----+--------+----------------------+
| 1 | Alice | alice@example.com | <--- row 1
| 2 | Bob | bob@example.com | <--- row 2
+----+--------+----------------------+
PRIMARY KEY: id
TABLE: orders
+----+---------+--------+
| id | user_id | total |
+----+---------+--------+
| 1 | 1 | 120.00 |
| 2 | 1 | 75.50 |
| 3 | 2 | 200.00 |
+----+---------+--------+
PRIMARY KEY: id
FOREIGN KEY: user_id → users.id
This design approach is typically structured using normalization principles to reduce duplication and maintain consistency. Normalization reduces data duplication and improves consistency by ensuring that each piece of information is stored in one place.
- 1NF: Atomic values (no arrays or nested objects) — simplifies queries
- 2NF: No partial dependency on primary key — reduces redundancy
- 3NF: No transitive dependencies — improves data consistency
While strict normalization is not always required in practice, the core idea — avoid duplication and maintain consistency — is essential for scalable system design.
SQL Queries and Data Access
SQL (Structured Query Language) provides a powerful way to define, retrieve, and manipulate data in relational databases. Before querying data, we define a schema that describes how data is structured. Once the schema is defined, SQL allows performing standard operations on the data:
- SELECT: retrieve data
- INSERT: add new records
- UPDATE: modify existing data
- DELETE: remove records
Example: Users and Orders
Schema definitions:
-- Users table: stores application users
CREATE TABLE users (
id SERIAL PRIMARY KEY, -- unique user identifier
name TEXT NOT NULL, -- user's name
email TEXT UNIQUE NOT NULL -- unique email address
);
-- Orders table: stores user purchases
CREATE TABLE orders (
id SERIAL PRIMARY KEY, -- unique order identifier
user_id INT REFERENCES users(id), -- relation to users table
total NUMERIC NOT NULL, -- order amount
created_at TIMESTAMP DEFAULT NOW() -- order creation time
);
INSERT (create a new user and order):
INSERT INTO users (name, email)
VALUES ('Alice', 'alice@example.com');
INSERT INTO orders (user_id, total)
VALUES (1, 150.00);
SELECT (retrieve users and their orders):
SELECT u.name, o.total
FROM users u
JOIN orders o ON u.id = o.user_id
WHERE o.total > 100;
UPDATE (modify order amount):
UPDATE orders
SET total = 200.00
WHERE id = 1;
DELETE (remove an order):
DELETE FROM orders
WHERE id = 1;
These operations, combined with joins and aggregations, make SQL a powerful tool for working with structured data.
ACID Transactions
One of the most important properties of SQL databases is support for ACID transactions, which ensure reliability and consistency during data operations.
- Atomicity: All operations in a transaction succeed, or none are applied
- Consistency: Database remains in a valid state before and after a transaction
- Isolation: Concurrent transactions do not interfere with each other
- Durability: Once committed, data persists even in case of system failure
These guarantees are critical for systems like payments, banking, and order processing where correctness is more important than raw speed. For more information, see Database Transactions.
Example: Money Transfer Between Accounts
Schema definitions and data:
-- Table: accounts
-- Stores user balances for a simple banking system
CREATE TABLE accounts (
id SERIAL PRIMARY KEY, -- unique account identifier
user_name TEXT NOT NULL, -- account owner name
balance NUMERIC NOT NULL -- current account balance
);
-- Example initial data
INSERT INTO accounts (user_name, balance)
VALUES
('Sender', 1000),
('Receiver', 500);Transaction:
BEGIN TRANSACTION;
-- Deduct money from sender account (id = 1)
UPDATE accounts
SET balance = balance - 100
WHERE id = 1;
-- Add money to receiver account (id = 2)
UPDATE accounts
SET balance = balance + 100
WHERE id = 2;
COMMIT;If any step fails before COMMIT, the database will roll back the entire transaction, ensuring no partial updates occur. This guarantees atomicity and protects the system from inconsistent states during failures.
Indexing and Performance
Indexes are data structures used by SQL databases to speed up data retrieval. Instead of scanning an entire table row by row, the database can use an index to quickly locate matching records.
Indexes are especially important in large datasets where full table scans become too slow for production workloads.
- Primary Index: Automatically created on primary keys for fast row lookup
- Secondary Index: Improves performance for queries on non-key columns
- Composite Index: Optimizes queries that filter by multiple columns
However, indexes are a trade-off: they improve read performance but introduce overhead for writes, since every insert, update, or delete must also update index structures.
Example: Index on Email Lookup
A common use case is searching users by email. Without an index, this requires scanning the entire table.
CREATE TABLE users (
id SERIAL PRIMARY KEY, -- automatically indexed
name TEXT NOT NULL,
email TEXT UNIQUE NOT NULL -- UNIQUE also creates an index
);
-- Optional explicit index (if not using UNIQUE constraint)
CREATE INDEX idx_users_email ON users(email);
Now consider a query that retrieves a user by email:
-- Fast lookup using index
SELECT *
FROM users
WHERE email = 'alice@example.com';
With the index in place, the database avoids scanning all rows and directly navigates the index structure.
Performance impact:
Without index → full table scan (linear time complexity)
With index → indexed lookup (logarithmic or near constant depending on engine)
Example: Composite Index for Real Queries
When queries filter by multiple columns, a composite index can significantly improve performance.
-- Composite index on two columns
CREATE INDEX idx_users_name_email ON users(name, email);
-- Efficient because it matches index order (name + email)
SELECT *
FROM users
WHERE name = 'Alice'
AND email = 'alice@example.com';
However, this index would not be equally effective if only email is used in the query, because index order matters.
Key trade-off: indexes improve query speed but increase storage usage and slow down writes, since each modification requires updating index structures.
Scaling SQL Databases
SQL databases are traditionally scaled vertically, but modern architectures also support horizontal scaling strategies.
- Vertical scaling: increase CPU/RAM of a single instance
- Read replicas: distribute read traffic
- Sharding: split data across multiple databases
Example: Vertical Scaling
Vertical scaling does not change the application or schema — it simply upgrades the database machine to handle more load.
Before:
DB Instance → 2 CPU / 4 GB RAM
After:
DB Instance → 8 CPU / 32 GB RAM
This approach is simple but has physical limits — eventually, you cannot scale a single machine further.
Example: Read Replicas
Read replicas allow read-heavy workloads to be distributed across multiple database copies while keeping a single write source.
(Writes)
Application ─────────→ Primary DB (PDB)
│
├──→ Read Replica 1 (RR1)
├──→ Read Replica 2 (RR2)
└──→ Read Replica 3 (RR3)
Example flow:
-- Write always goes to primary (PDB)
INSERT INTO PDB.users (name, email)
VALUES ('Alice', 'alice@example.com');
-- Reads can go to replicas (RR1, RR2, RR3)
SELECT * FROM users;
This improves read performance but introduces slight replication lag between primary and replicas.
Example: Sharding
Sharding splits a database into multiple smaller databases based on a shard key (e.g. user_id).
Shard 1 (user_id 1–1M) → DB-A
Shard 2 (user_id 1M–2M) → DB-B
Shard 3 (user_id 2M–3M) → DB-C
Example routing logic:
-- Pseudo routing logic
IF user_id < 1000000 THEN DB-A
ELSE IF user_id < 2000000 THEN DB-B
ELSE DB-C
Sharding improves scalability but adds complexity in queries, joins, and data rebalancing.
Scaling SQL systems requires careful planning, especially when dealing with large datasets and high traffic.
When to Use SQL Databases
SQL databases are the best choice when your system requires structured data and strong consistency.
- Financial systems and payments
- User accounts and authentication
- Inventory and order management
- Reporting and analytics queries
They are especially effective when relationships between data entities are important.
Advantages of SQL Databases
- Strong consistency with ACID guarantees
- Powerful querying using joins and aggregations
- Mature ecosystem and tooling
- Clear data structure and schema enforcement
Limitations of SQL Databases
- Schema changes require migrations
- Horizontal scaling is more complex
- Less flexible for unstructured data
These limitations usually become relevant only at larger scale or in highly dynamic systems.
SQL vs NoSQL (High-Level Comparison)
SQL and NoSQL databases solve different problems and come with different trade-offs. SQL focuses on structured data and strong consistency, while NoSQL prioritizes flexibility and scalability.
| Aspect | SQL | NoSQL |
|---|---|---|
| Data model | Structured (tables) | Flexible (documents, key-value) |
| Schema | Predefined | Dynamic |
| Consistency | Strong (ACID) | Often eventual |
| Querying | Rich (joins, aggregations) | Limited, pattern-based |
This comparison highlights why SQL is often preferred for systems requiring strong consistency and complex queries. For a deeper comparison, see SQL vs NoSQL for MVP: How to Choose the Right Database.
Common SQL Databases
Several SQL database systems are widely used in production:
- PostgreSQL: advanced features and strong consistency
- MySQL: widely adopted and easy to use
- SQLite: lightweight and embedded
- Microsoft SQL Server: enterprise-focused
Each system has its own strengths, but they all follow the same relational principles. For a deeper comparison, see RDBMS (SQL) Engines: Pros, Cons, and Use Cases.
Summary
SQL databases remain a cornerstone of modern application development due to their reliability, structure, and flexibility.
- Best for structured data and relationships
- Provide strong consistency guarantees
- Support powerful and flexible queries
Core idea: SQL databases trade upfront schema design for long-term clarity, consistency, and maintainability.


Comments (0)