Key-Value NoSQL Databases — Patterns, Trade-Offs, and Real-World Use Cases
By Oleksandr Andrushchenko — Published on

Key-value NoSQL databases store data as simple pairs: a unique key and a value. They are designed for fast lookups, predictable access patterns, horizontal scalability, and low-latency reads and writes.
This article explains how key-value databases work, where they fit in system design, when to use them, when to avoid them, and how they compare with relational databases.
Table of Contents
- Key-Value Database Fundamentals
- How Key-Value Stores Work
- Real-World Use Cases
- Popular Key-Value Databases
- Data Modeling
- Advantages and Limitations
- SQL vs Key-Value Databases
- Architecture Examples
- Production Checklist
- Conclusion
Key-Value Database Fundamentals
What Is a Key-Value Database?
A key-value database is a database where each record is stored under a unique key. The database does not usually care much about the internal structure of the value. The value can be a string, number, JSON document, binary object, list, hash, set, or another serialized format depending on the database.
key: user:123
value: {"id": 123, "name": "Alex", "email": "alex@example.com"}The main idea is simple: if the application knows the key, it can retrieve the value very quickly. This makes key-value databases excellent for predictable access patterns such as sessions, cache entries, counters, shopping carts, feature flags, and rate limits.
Basic Concept
Key-value databases are optimized around direct access. Instead of asking complex questions like “find all orders where status is pending and total is greater than $100,” the application asks for a known key such as cart:user:123 or session:abc123.
Application
|
GET cart:user:123
|
Key-Value Database
|
Return cart objectKey takeaway: key-value databases are extremely powerful when the application knows exactly what it wants to read or write.
Why It Is Fast
Key-value databases are fast because they avoid many expensive database operations. They usually do not need joins, query planning, complex relational constraints, or multi-table scans. The access pattern is direct: find a key and return its value.
| Reason | Why It Helps |
|---|---|
| Direct key lookup | The database can locate data quickly by key |
| Simple data model | Less query-planning overhead |
| Easy partitioning | Keys can be distributed across many nodes |
| Memory-first options | Systems like Redis can serve data from RAM |
| Predictable access patterns | Performance is easier to reason about |
How Key-Value Stores Work
Key Lookups
The most common operation in a key-value database is a lookup by key. The application sends a key, and the database returns the associated value.
GET user:123
GET session:token:abc
GET cart:user:123
GET rate_limit:ip:192.168.1.10This is different from relational databases, where queries often filter, join, sort, and aggregate data. Key-value systems are intentionally less flexible, but much faster for the access patterns they support.
Partitioning and Sharding
Key-value databases are easy to partition because the key can be hashed to decide where the data lives. This makes horizontal scaling much simpler than in systems that need complex joins or cross-table transactions.
hash(user:123) -> Node A
hash(user:456) -> Node B
hash(user:789) -> Node CFor example, a distributed key-value store can spread millions of session records across many nodes. Each node owns a subset of the key space. When traffic grows, the system can add more nodes and redistribute keys.
Replication
Replication means storing copies of data on multiple nodes. This improves availability and read scalability. If one node fails, another replica can continue serving requests.
Client
|
Primary Node
|
+-------------+-------------+
| |
Replica 1 Replica 2The trade-off is consistency. Some systems prioritize strong consistency, while others prioritize availability and eventual consistency. The right choice depends on the use case. A cache can tolerate stale data more easily than a payment record.
TTL and Expiration
Many key-value databases support TTL, or time to live. TTL automatically deletes a key after a specified time. This is useful for sessions, cache entries, temporary tokens, rate-limit counters, and verification codes.
SET session:abc123 "{...}" EX 3600
The key expires after 3600 seconds.Rule of thumb: if data is temporary by nature, use TTL instead of relying only on manual cleanup jobs.
Real-World Use Cases
Caching
Caching is one of the most common use cases for key-value databases. The application stores frequently requested data in a fast key-value store to avoid repeated database queries or expensive computations.
User Request
|
Application
|
GET product:123
|
Redis
|
Cache hit -> return product
Cache miss -> query database, store result, return productFor example, an e-commerce platform can cache product details, category pages, user permissions, or dashboard summaries. This reduces load on the primary database and improves response time.
User Sessions
Session storage is another natural fit. The application stores session data under a token or session ID.
key: session:abc123
value: {"user_id": 123, "role": "admin", "expires_at": "2026-06-21T20:00:00Z"}This works well because session reads are usually direct lookups. The application receives a session token and needs to retrieve the corresponding session object quickly.
Shopping Carts
Shopping carts are often modeled as key-value records because the application usually needs the entire cart by user ID or cart ID.
key: cart:user:123
value:
{
"user_id": 123,
"items": [
{"product_id": 10, "quantity": 2},
{"product_id": 15, "quantity": 1}
],
"updated_at": "2026-06-21T15:30:00Z"
}This is efficient because the cart can be retrieved with one lookup. No joins are required to display the current cart state.
Feature Flags
Feature flags are often read many times and updated less frequently. A key-value database can store flag configuration and serve it quickly to application instances.
feature:checkout:new-flow
feature:search:ranking-v2
feature:user:123:beta-accessFor example, a backend service can check whether a new checkout flow is enabled before rendering a page or processing an order. Because these checks happen frequently, low-latency reads are important.
Rate Limiting
Rate limiting is a classic Redis use case. The application increments a counter for a user, IP address, API key, or tenant and rejects requests when the counter exceeds a limit.
key: rate_limit:user:123:minute:2026-06-21T15:30
value: 47
ttl: 60 secondsAPI Request
|
Increment counter
|
Check limit
|
Allow or rejectThis works well because counters are small, frequently updated, and naturally expire after a time window.
Leaderboards
Some key-value databases support data structures beyond simple strings. Redis, for example, supports sorted sets, which are useful for leaderboards, rankings, and score-based queries.
leaderboard:game:weekly
user:123 -> 9500
user:456 -> 8700
user:789 -> 7600This is still key-value style access, but with richer operations provided by the database.
Popular Key-Value Databases
Redis
Redis is commonly used for caching, sessions, queues, counters, rate limiting, pub/sub, and leaderboards. It is fast because it primarily serves data from memory, and it provides useful data structures such as strings, hashes, lists, sets, sorted sets, and streams.
DynamoDB
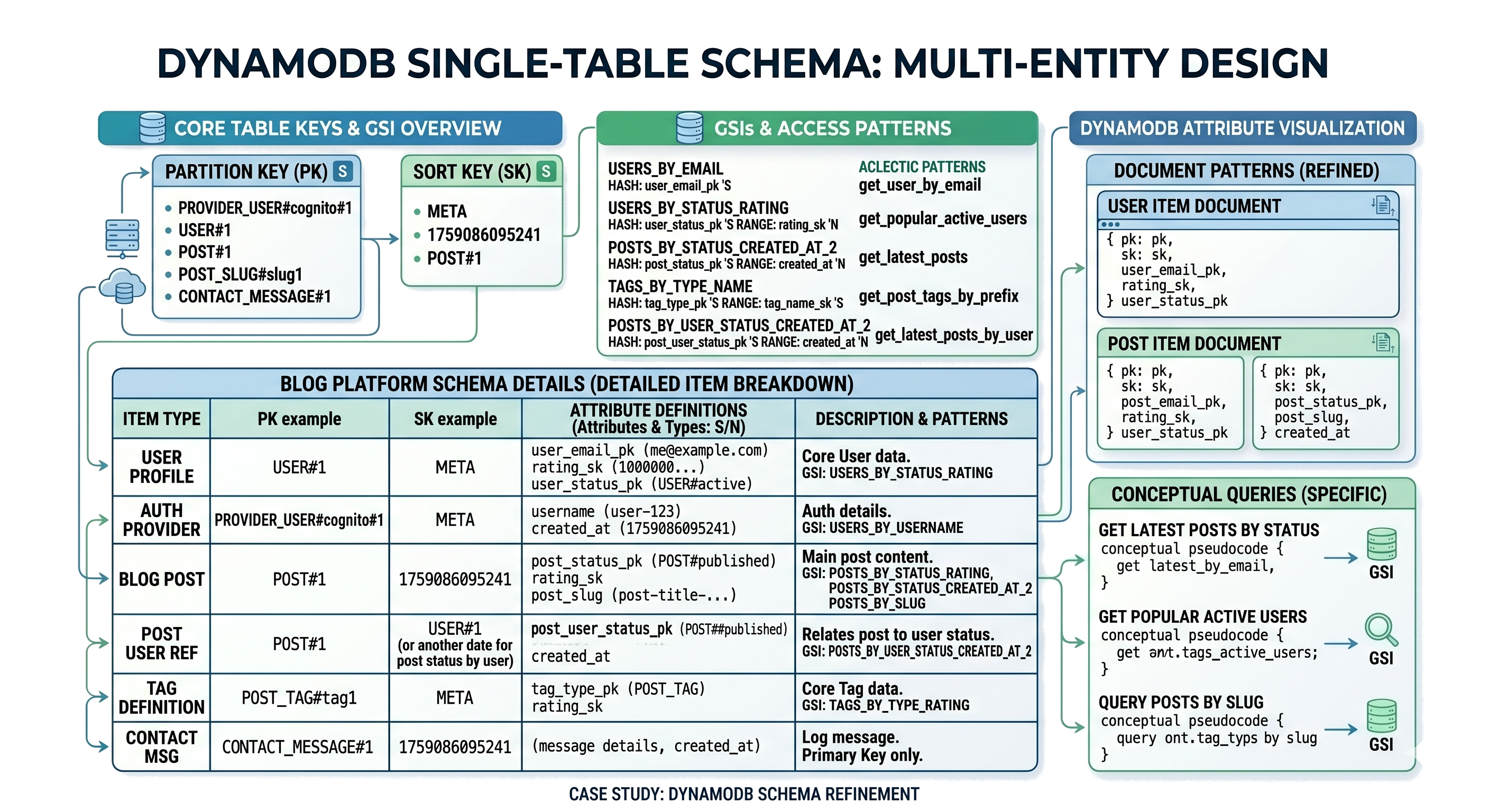
DynamoDB is AWS’s managed NoSQL database. It is often used as a key-value and document database. It is designed for predictable access patterns, high scale, and low operational overhead. DynamoDB works best when partition keys, sort keys, and access patterns are designed before implementation.
Aerospike
Aerospike is a high-performance NoSQL database often used for low-latency workloads such as ad tech, fraud detection, real-time profiles, and large-scale key-value access.
Riak
Riak is a distributed key-value database known for availability-oriented design. It is often discussed in the context of distributed systems, replication, conflict resolution, and eventual consistency.
| Database | Common Use Cases | Strength |
|---|---|---|
| Redis | Cache, sessions, counters, rate limits | Very low latency and rich data structures |
| DynamoDB | Serverless apps, user data, events, carts | Managed scalability and predictable access |
| Aerospike | Real-time profiles, ad tech, fraud detection | High throughput and low latency |
| Riak | Highly available distributed storage | Availability and fault tolerance |
Data Modeling
Composite Keys
Because key-value databases usually do not support joins, the key design is extremely important. A common strategy is to use composite keys that include entity type, ID, and access pattern.
user:123:profile
user:123:sessions
cart:user:123
tenant:42:settings
rate_limit:api_key:abc123
product:789:detailsThe key should make the access pattern obvious. If engineers cannot understand what a key represents, debugging production issues becomes harder.
Key Naming Strategies
Good key naming helps with organization, debugging, and avoiding collisions. Use predictable prefixes and include the dimensions that affect the value.
| Pattern | Example | Use Case |
|---|---|---|
| Entity key | user:123 |
Single object lookup |
| Scoped key | tenant:42:user:123 |
Multi-tenant isolation |
| Time-window key | rate:user:123:2026-06-21T15:30 |
Rate limiting |
| Versioned key | homepage:v3 |
Cache invalidation |
| Relationship key | user:123:followers |
Precomputed relationships |
Denormalization
Key-value databases often require denormalization, which means storing data in the shape needed by the application. Instead of joining data at read time, the system stores a ready-to-read value.
key: product_page:123
value:
{
"product": {...},
"price": {...},
"top_reviews": [...],
"recommendations": [...]
}This can make reads extremely fast, but updates become more complex. If product price changes, every cached or denormalized value that contains the price may need to be updated or invalidated.
TTL and Expiration Strategy
TTL is not just a cleanup mechanism. It is also a correctness and cost control tool. Short TTLs keep data fresher but increase backend load. Long TTLs reduce load but increase stale-data risk.
| Data Type | Typical TTL | Reason |
|---|---|---|
| Session | Minutes to hours | Should expire automatically |
| Rate-limit counter | Seconds to minutes | Matches rate-limit window |
| Product description cache | Minutes to hours | Changes occasionally |
| Inventory cache | Seconds or direct read | Stale data can break checkout |
| Analytics summary | Minutes to hours | Some delay is acceptable |
Advantages and Limitations
Advantages
- Very fast key-based access. Reads and writes are optimized for direct lookup.
- Simple data model. The application stores and retrieves values by key.
- Easy horizontal scaling. Keys can be partitioned across nodes.
- Good fit for temporary data. TTL works well for sessions, tokens, and counters.
- Predictable performance. When access patterns are known, performance is easier to reason about.
Limitations
- No joins. Related data must often be duplicated or precomputed.
- Limited querying. You usually cannot ask arbitrary questions like in SQL.
- Access patterns must be known. Poor key design leads to painful refactoring.
- Data duplication is common. This improves reads but complicates updates.
- Consistency varies by system. Some key-value databases prioritize availability over strict consistency.
When Not to Use Key-Value Databases
Key-value databases are not a good fit when the application needs complex filtering, joins, ad-hoc reports, relational constraints, or flexible querying over many fields. In those cases, a relational database or document database may be better.
| Requirement | Better Choice |
|---|---|
| Complex joins | Relational database |
| Ad-hoc analytics | Analytical database or SQL engine |
| Strong relational constraints | Relational database |
| Fast lookup by known key | Key-value database |
| Temporary counters or sessions | Key-value database |
SQL vs Key-Value Databases
Relational databases and key-value databases solve different problems. PostgreSQL is excellent when the system needs flexible queries, joins, transactions, constraints, and reporting. Key-value databases are excellent when the system needs very fast access by known keys.
| Feature | Key-Value Database | Relational Database |
|---|---|---|
| Primary access pattern | Key lookup | Flexible queries |
| Joins | No | Yes |
| Horizontal scaling | Usually easier | More difficult |
| Latency | Very low for key lookups | Depends on query complexity |
| Complex queries | Limited | Excellent |
| Transactions | Often limited or scoped | Strong support |
| Schema | Flexible or application-defined | Database-enforced |
| Best use case | Sessions, cache, counters, carts | Orders, payments, reporting, relational data |
Important recommendation: do not choose key-value databases just because they sound scalable. Choose them when the access pattern is simple, known, and key-based.
Architecture Examples
E-Commerce Shopping Cart
A shopping cart is a good key-value use case because the application usually needs the whole cart by user ID or cart ID. The cart can be stored in Redis or DynamoDB, while the final order is stored in a relational database after checkout.
User
|
Application
|
GET cart:user:123
|
Key-Value Store
|
Return cartCheckout flow:
Cart in Redis/DynamoDB
|
Validate prices and inventory
|
Create order in PostgreSQL
|
Clear cart keyWhy this works: cart reads are fast, the cart object is naturally accessed by key, and the final order can still be stored in a transactional relational database.
Session Store
Session storage is another common architecture. Application servers remain stateless because session data is stored in a shared key-value database.
User
|
Load Balancer
|
Application Servers
|
Redis Session StoreThis allows any application instance to handle any request. If one server fails, another server can read the same session from the shared store.
API Rate Limiter
Rate limiting usually needs fast counters with expiration. A key-value database can increment a counter and automatically expire it after the time window ends.
API Request
|
Get user/API key/IP
|
Increment rate-limit key
|
If count <= limit: allow
If count > limit: rejectrate_limit:user:123:minute:2026-06-21T15:30 -> 47This pattern is common in API gateways, SaaS platforms, login protection, payment APIs, and public developer APIs.
Cache-Aside Pattern
Key-value stores are frequently used in the cache-aside pattern. The application checks the cache first. On a miss, it reads from the database, stores the result, and returns it.
Application
|
GET product:123 from Redis
|
Cache miss
|
Read product from PostgreSQL
|
SET product:123 in Redis
|
Return productThis improves read performance while keeping the relational database as the source of truth.
Production Checklist
- Start from access patterns. Know exactly which keys the application will read and write.
- Use clear key naming. Include entity type, ID, tenant, version, or time window when needed.
- Set TTLs for temporary data. Sessions, tokens, counters, and cache entries should usually expire automatically.
- Do not store critical relational data only in cache. Use durable storage for orders, payments, and financial records.
- Plan invalidation. Cached values must be updated or expired when source data changes.
- Watch hot keys. A single extremely popular key can overload one partition or node.
- Limit value size. Very large values increase latency, memory usage, and network transfer.
- Monitor memory usage and eviction rate. Unexpected evictions can break assumptions.
- Use rate limits and backpressure. Protect the key-value store from traffic spikes.
- Choose consistency intentionally. A cache can tolerate stale data; payment state usually cannot.
- Keep source-of-truth decisions clear. Decide whether the key-value database is a cache, primary database, or temporary state store.
Conclusion
Key-value databases are not general-purpose replacements for relational databases. They are specialized systems optimized for fast key-based access, predictable performance, and horizontal scalability.
They are excellent for caching, sessions, shopping carts, feature flags, rate limiting, counters, and other workloads where the application knows the exact key it needs. They are weaker when the system needs joins, complex queries, relational constraints, and ad-hoc reporting.
Key takeaway: if your application always knows exactly which record it needs, a key-value database can be one of the fastest and simplest storage solutions available. If your application needs flexible querying and relationships, a relational database is usually the better starting point.



Comments (0)