NoSQL Engines Compared: Trade-offs, Performance, and Use Cases
By Oleksandr Andrushchenko — Published on — Modified on
NoSQL engines provide different trade-offs in latency, consistency, scalability, and query flexibility. Choosing the right engine requires understanding data access patterns, workload characteristics, and operational complexity, not just database type.
Selecting the Right NoSQL Engine
Choosing the right NoSQL engine directly impacts latency, cost efficiency, scalability, and operational complexity. Each engine is optimized for specific access patterns and workloads, so understanding system requirements is more important than focusing on features alone. For a foundational overview, see NoSQL database types and trade-offs.
This article explores widely used NoSQL engines in system design:
| Engine | Type | Strengths | Weaknesses | Best Use | Reads | Writes | Consistency |
|---|---|---|---|---|---|---|---|
| MongoDB | Document | Flexible schema, rich queries, indexing | Memory-heavy, joins limited | Dynamic applications | Indexed queries | Moderate | Strong/Eventual |
| Redis | Key-Value | Ultra-low latency, in-memory | Limited persistence, memory-bound | Caching, sessions | Key lookup | High | Strong (single node) |
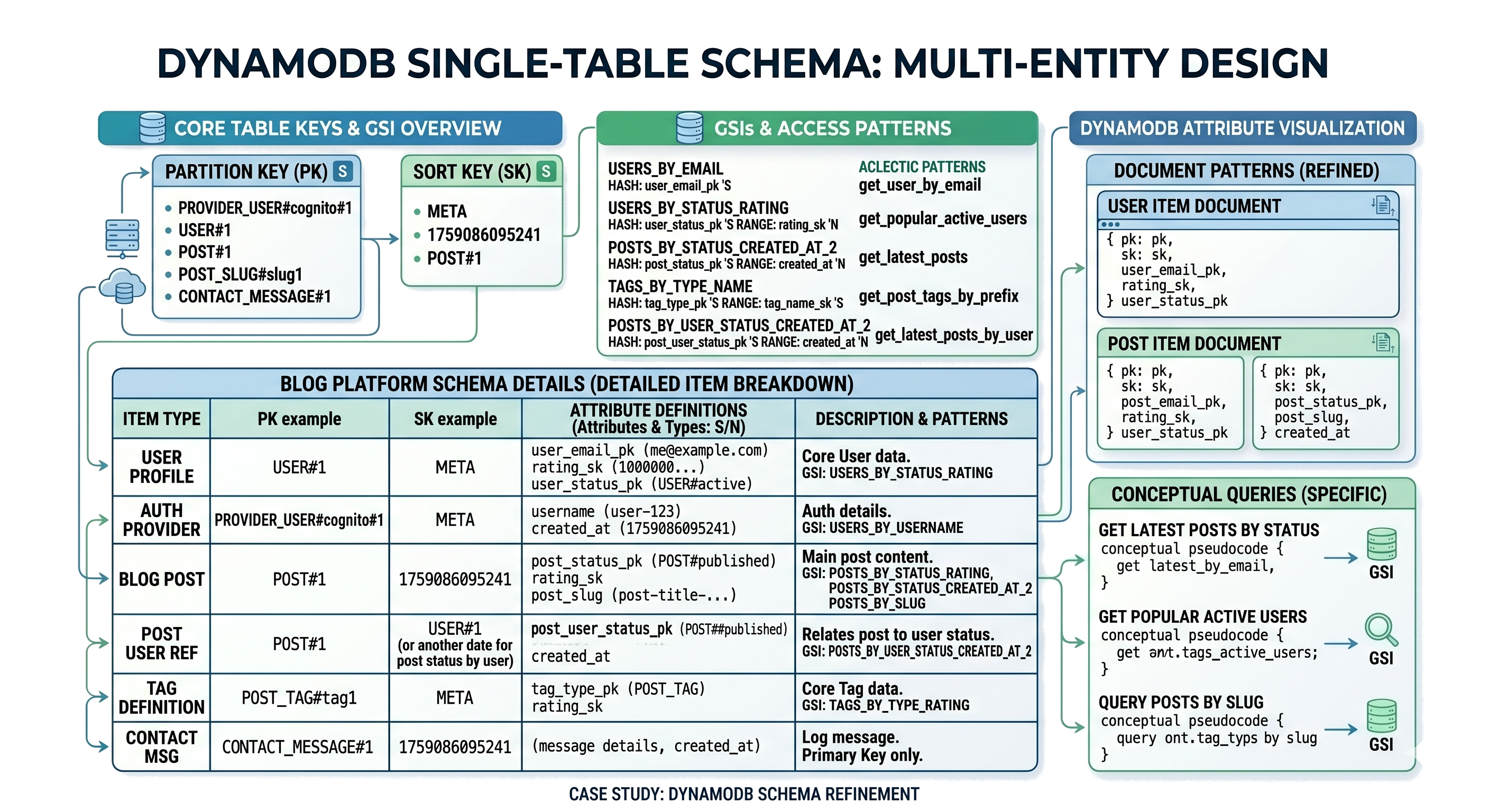
| DynamoDB | Key-Value / Document | Serverless, auto-scaling | Access pattern constraints | High-scale apps | Key + index | High | Eventual/Strong |
| Cassandra | Column-Family | High write throughput, distributed | Complex modeling | Time-series, logs | Partition-based | Very high | Tunable |
| Neo4j | Graph | Relationship queries, graph traversal | Scaling limitations | Graph workloads | Traversal | Moderate | Strong |
| Couchbase | Document | In-memory + disk, N1QL queries, caching | Operational complexity | Low-latency apps | Key + query | High | Eventual |
| Cosmos DB | Multi-model | Global distribution, multi-API | Cost, vendor lock-in | Global apps | API-based | High | Tunable |

1. MongoDB
MongoDB is a document-oriented database optimized for flexible schemas and developer productivity. It supports rich queries, secondary indexes, and aggregation pipelines, making it suitable for applications requiring fast iteration and evolving data models.
Advantages
- Schema flexibility with JSON-like documents.
- Rich querying and aggregation framework.
- Secondary indexes for efficient reads.
- Strong ecosystem and tooling.
Disadvantages
- Joins are limited compared to relational databases.
- Memory usage increases with indexing.
- Performance depends heavily on schema design.
When to Use / Real-World Use Cases
- Content platforms and CMS systems.
- User profile and personalization services.
- Rapid prototyping with changing schemas.
- Product catalogs with dynamic attributes.
Example
Aggregation pipeline to calculate total order value per user:
db.orders.aggregate([
{ $group: { _id: "$userId", total: { $sum: "$amount" } } }
])2. Redis
Redis is an in-memory key-value store designed for extremely low latency. It supports multiple data structures and is commonly used for caching, queues, and real-time analytics where sub-millisecond response times are required.
Advantages
- Sub-millisecond latency.
- Rich data structures (lists, sets, hashes).
- Simple and predictable performance.
- Supports pub/sub and streams.
Disadvantages
- Limited by available memory.
- Persistence is optional and less robust.
- Not suitable for complex queries.
When to Use / Real-World Use Cases
- Caching frequently accessed data.
- Session storage in distributed systems.
- Rate limiting and counters.
- Real-time leaderboards.
Example
Atomic counter for tracking page views:
INCR page:home:views3. DynamoDB
DynamoDB is a fully managed key-value and document database designed for massive scale. It delivers consistent low latency and automatic scaling, but requires careful access pattern design upfront to avoid performance bottlenecks.
Advantages
- Serverless with automatic scaling.
- Consistent low-latency performance.
- Built-in replication and high availability.
- Fine-grained access control and integration with cloud services.
Disadvantages
- Strict access pattern requirements.
- Complex query patterns require additional indexes.
- Cost can grow with throughput usage.
When to Use / Real-World Use Cases
- High-scale serverless applications.
- Event-driven architectures.
- Gaming backends with high request rates.
- IoT platforms ingesting large volumes of data.
Example
Query using partition key and sort key:
Query({
TableName: "Orders",
KeyConditionExpression: "userId = :uid",
ExpressionAttributeValues: {
":uid": "u123"
}
})4. Cassandra
Cassandra is a distributed column-family database optimized for high write throughput and fault tolerance. It uses a peer-to-peer architecture and tunable consistency levels, making it suitable for globally distributed, write-heavy systems.
Advantages
- High availability with no single point of failure.
- Excellent write performance.
- Scales linearly across nodes.
- Tunable consistency levels.
Disadvantages
- Data modeling is query-driven and complex.
- Limited support for ad-hoc queries.
- Requires operational expertise.
When to Use / Real-World Use Cases
- Time-series and monitoring systems.
- Write-heavy analytics pipelines.
- Messaging and event logging systems.
- Global applications requiring multi-region replication.
Example
Table optimized for time-series queries:
CREATE TABLE events (
user_id text,
event_time timestamp,
event_type text,
PRIMARY KEY (user_id, event_time)
);5. Neo4j
Neo4j is a graph database designed for storing and querying relationships. It excels at traversals and connected data, enabling efficient execution of queries that would require multiple joins in relational systems.
Advantages
- Optimized for relationship queries.
- Expressive query language (Cypher).
- Flexible schema for nodes and edges.
- Efficient graph traversal algorithms.
Disadvantages
- Not optimized for simple key-value workloads.
- Scaling horizontally is challenging.
- Memory usage can grow with graph size.
When to Use / Real-World Use Cases
- Social networks and recommendations.
- Fraud detection systems.
- Knowledge graphs.
- Dependency and network analysis.
Example
Find shortest path between two users:
MATCH p=shortestPath(
(a:User {id:"u1"})-[*]-(b:User {id:"u2"})
)
RETURN p6. Couchbase
Couchbase is a distributed document database combining in-memory performance with durable storage. It supports SQL-like queries via N1QL and built-in caching, making it suitable for low-latency, high-throughput applications requiring flexible querying.
Advantages
- Integrated cache and database model.
- SQL-like query language (N1QL).
- High throughput with memory-first architecture.
- Flexible document storage.
Disadvantages
- Operational complexity in cluster management.
- Smaller ecosystem compared to MongoDB.
- Query performance depends on indexing strategy.
When to Use / Real-World Use Cases
- Real-time user profile systems.
- Low-latency web and mobile backends.
- Caching with persistence.
- Interactive applications with mixed workloads.
Example
N1QL query to fetch active users:
SELECT name, email
FROM users
WHERE status = "active";7. Cosmos DB
Cosmos DB is a globally distributed, multi-model database offering multiple APIs (SQL, MongoDB, Cassandra, Gremlin). It provides tunable consistency and automatic global replication, making it suitable for globally distributed applications.
Advantages
- Global distribution with multi-region writes.
- Tunable consistency levels.
- Multiple APIs for different data models.
- Low-latency reads worldwide.
Disadvantages
- Cost can increase significantly at scale.
- Vendor lock-in within Azure ecosystem.
- Complex capacity and RU planning.
When to Use / Real-World Use Cases
- Globally distributed applications.
- Multi-region SaaS platforms.
- Applications requiring low-latency global access.
- Multi-model workloads in a single system.
Example
Query using SQL API:
SELECT c.id, c.name
FROM c
WHERE c.region = "US"Conclusions
NoSQL engines differ significantly in performance characteristics, consistency models, and operational complexity. Selecting the right engine requires aligning data access patterns, scalability requirements, and system constraints with the strengths and limitations of each technology.



Comments (0)