NoSQL Databases: Types, Trade-offs, and Use Cases
By Oleksandr Andrushchenko — Published on — Modified on
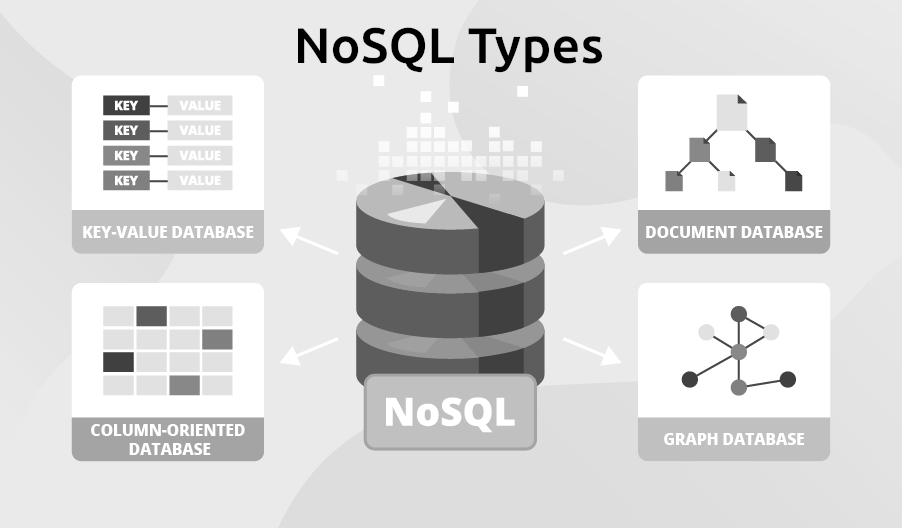
NoSQL databases are designed to handle large-scale, high-velocity, and unstructured data that traditional relational databases struggle with. They often sacrifice strict consistency for scalability, flexibility, and performance, making them ideal for modern distributed systems.
Selecting the Right NoSQL Type
Choosing the right NoSQL type directly impacts scalability, query flexibility, data modeling complexity, and system performance. Each type is optimized for a specific access pattern, so understanding your workload is more important than focusing on features alone.
In this article, we will explore the four primary NoSQL database types used in system design:
| Name | Strengths | Weaknesses | Best Use | Reads | Writes | Examples |
|---|---|---|---|---|---|---|
| Document | Flexible schema, rich queries, horizontal scaling | Joins are limited, complex transactions | Flexible, evolving schemas | Indexed queries | Moderate | MongoDB, Couchbase |
| Key-Value | Simple, low-latency, cache-friendly, horizontal scaling | Limited query capability, no relationships | Session, cache | Simple key lookups | High | Redis, DynamoDB |
| Column-Family | Efficient for large datasets, time-series, horizontal scaling | Complex schema design, learning curve | Time-series, logs | Range queries | High | Cassandra, HBase |
| Graph | Complex relationship queries, traversal, flexible schema | Not ideal for high-volume simple queries, harder to scale horizontally | Relationships, paths | Traversals | Moderate | Neo4j, Amazon Neptune |
1. Document Databases
Document databases store data in JSON, BSON, or XML documents, allowing flexible and nested data structures. Each document contains all necessary information, making it ideal for applications where data models evolve frequently.
Advantages
- Flexible, schema-less design.
- Supports complex nested data.
- Efficient reads with indexes on fields.
- High horizontal scalability.
Disadvantages
- Limited support for multi-document transactions.
- Joins across collections are complex or require manual work.
- Indexes can grow large with complex queries.
When to Use / Real-World Use Cases
- Content management systems (CMS) storing articles or pages.
- User profiles with varying attributes.
- E-commerce catalogs with dynamic product attributes.
- Event logging and analytics with evolving fields.
Example
MongoDB document storing a user profile:
{
"_id": "u123",
"name": "Alice",
"email": "alice@example.com",
"preferences": {
"notifications": true,
"theme": "dark"
},
"orders": [
{"id": "o1001", "total": 150.0},
{"id": "o1002", "total": 89.9}
]
}2. Key-Value Databases
Key-Value stores map unique keys to values, providing extremely fast access. They are optimized for low-latency retrieval and work well as caching layers or session stores in distributed systems.
Advantages
- Extremely fast reads and writes.
- Simple API and lightweight design.
- Highly scalable horizontally.
- Supports in-memory storage for ultra-low latency.
Disadvantages
- Limited query capabilities beyond key lookups.
- No relationships between data entities.
- Data structure often opaque to the database.
When to Use / Real-World Use Cases
- Session storage for web applications.
- Caching layer for frequently accessed data.
- Storing user preferences or configuration values.
- Leaderboards or counters in gaming apps.
Example
Redis storing a user session:
SET session:u123 "{"cart":[101,102],"last_login":"2026-03-22T12:00:00Z"}"
GET session:u1233. Column-Family Databases
Column-Family stores organize data into rows and dynamic columns. Each row can have a different set of columns, making it efficient for time-series data or wide tables and high-throughput write-heavy workloads.
Advantages
- High write throughput.
- Efficient storage for sparse datasets.
- Supports horizontal scaling with distributed architecture.
- Good for analytical and real-time queries on large datasets.
Disadvantages
- Complex schema design compared to relational databases.
- Query flexibility is limited; aggregation often requires external tools.
- Steeper learning curve for developers unfamiliar with columnar models.
When to Use / Real-World Use Cases
- IoT sensor data storage.
- Time-series metrics for monitoring platforms.
- High-volume write systems like recommendation engines.
- Event logging and analytical workloads.
Example
Cassandra table for storing temperature readings:
CREATE TABLE temperature_readings (
sensor_id text,
reading_time timestamp,
temperature double,
PRIMARY KEY (sensor_id, reading_time)
);
INSERT INTO temperature_readings (sensor_id, reading_time, temperature)
VALUES ('sensor1', '2026-03-22 12:00:00', 23.5);4. Graph Databases
Graph databases focus on relationships between data entities, storing nodes and edges. They are optimized for traversals and complex relationship queries, making them ideal for social networks, fraud detection, and recommendation systems.
Advantages
- Efficient for querying relationships and paths.
- Flexible schema with dynamic nodes and edges.
- Supports complex graph algorithms like shortest path or centrality.
- Can simplify queries that would require multiple joins in SQL.
Disadvantages
- Not optimized for high-volume simple key-value queries.
- Scaling horizontally can be complex.
- Graph algorithms can be memory intensive.
When to Use / Real-World Use Cases
- Social networks analyzing friend or follower connections.
- Fraud detection in financial systems.
- Recommendation engines leveraging user-product relationships.
- Supply chain networks and dependency graphs.
Example
Neo4j query to find friends-of-friends:
MATCH (a:Person {name:"Alice"})-[:FRIEND]->(b)-[:FRIEND]->(fof)
RETURN fof.nameConclusions
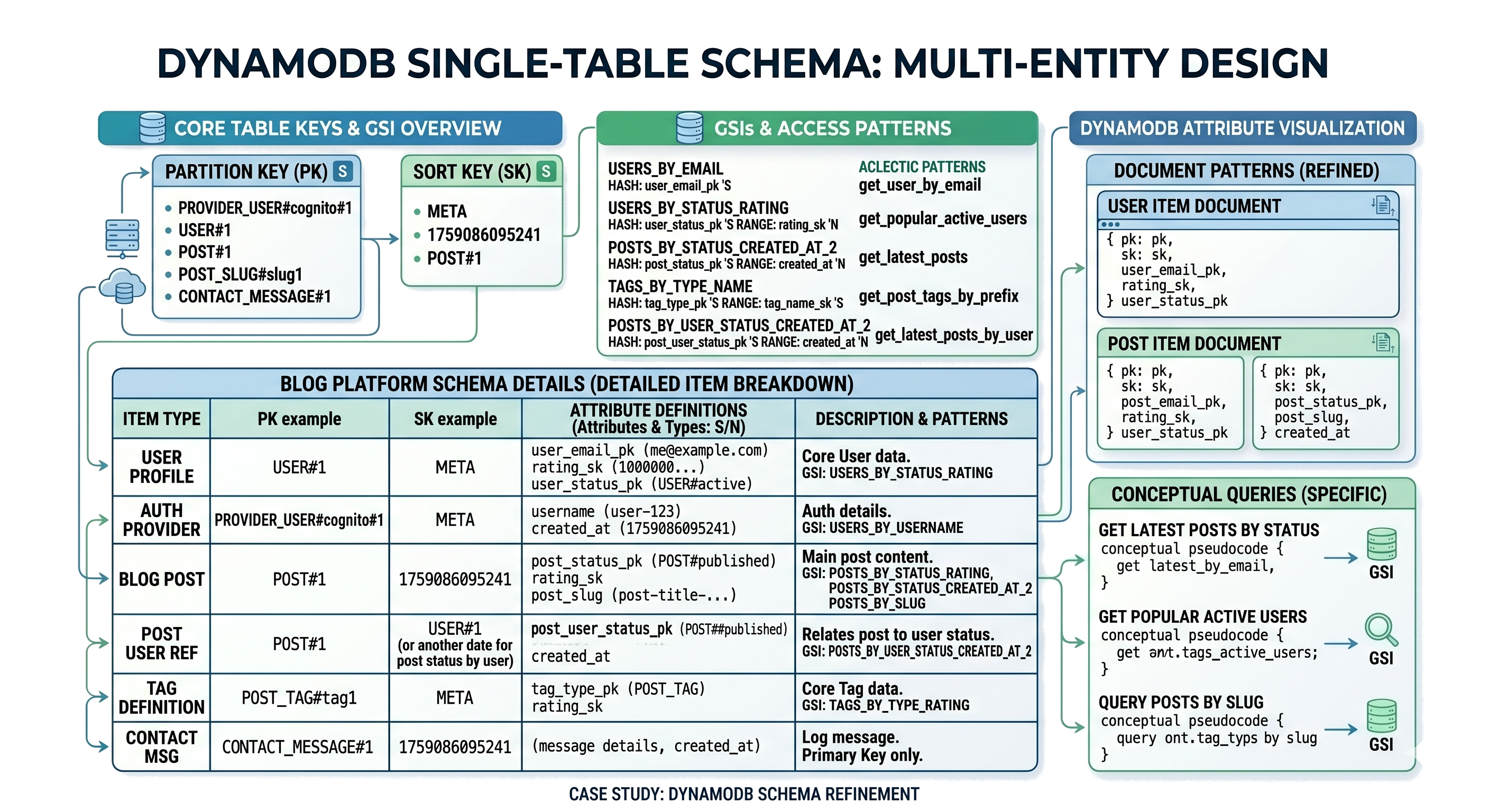
NoSQL databases offer flexibility, scalability, and performance for modern applications. Selecting the right type depends on data model, query patterns, and throughput needs. Document, Key-Value, Column-Family, and Graph databases each excel in distinct scenarios with clear trade-offs.




Comments (0)