Scalability for Dummies - Part 3: Cache
By Oleksandr Andrushchenko — Published on — Modified on
After following Scalability for Dummies - Part 2: Database, the database can now handle massive volumes of data and high concurrency. Despite this, users may still experience slow page loads when queries fetch large amounts of data. The bottleneck is no longer the database itself but the repeated retrieval of frequently accessed data — the solution is caching.
Why Caching Matters
Caching improves response times by storing frequently accessed data in a fast, in-memory store, reducing repeated database hits. For example, an e-commerce platform might cache product catalog data so that the server does not query the database for every page request during a flash sale. Without caching, even a horizontally scaled database can become overwhelmed under peak traffic.
Effective caching also reduces latency variability, improves throughput, and lowers operational costs by offloading read operations from the database.
Types of Caching Strategies
There are multiple caching strategies, each suited for different workloads and consistency requirements. Common approaches include:
- Time-to-Live (TTL) cache: Stores data for a predefined period. Ideal for frequently accessed but slowly changing data, such as daily trending items.
- Write-through cache: Updates both the cache and database simultaneously. Guarantees consistency but can increase write latency.
- Write-back cache: Updates only the cache initially and flushes changes to the database asynchronously. Reduces write latency but risks data loss in case of cache failure.
Choosing the right strategy depends on the acceptable trade-off between consistency, freshness, and latency.
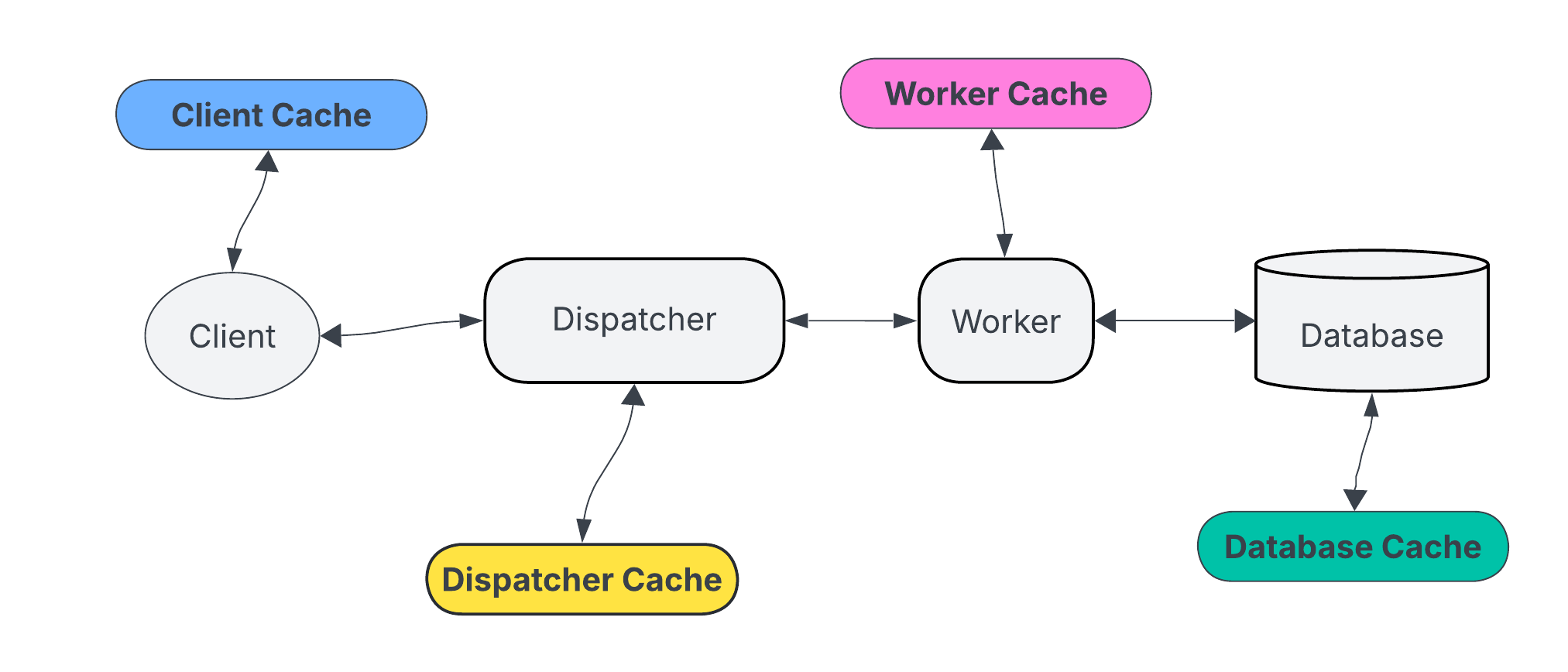
Cache Placement and Hierarchies
Caches can exist at multiple levels, including application-level memory, distributed caches, or edge/CDN caching. For instance, a news website may use Redis as a distributed cache for API responses and a CDN for static assets to serve content closer to users.
- Application-level cache: Fastest access, limited by local memory, suitable for ephemeral data.
- Distributed cache: Scales horizontally across nodes, supports shared access among servers.
- Edge/CDN cache: Reduces latency for globally distributed users, especially effective for static content.
Each layer adds complexity but can significantly reduce load on the database and improve user experience.
Cache Invalidation Strategies
One of the hardest problems in caching is keeping the cache consistent with the database. Cache invalidation strategies include:
- Time-based expiration: Items expire after a fixed TTL.
- Event-based invalidation: Updates to the database trigger cache refreshes.
- Manual invalidation: Developers explicitly remove or update cache entries when data changes.
For example, a ticket booking system might invalidate seat availability caches whenever a reservation is confirmed to avoid overselling.
Choosing a Cache Store
Several caching technologies exist, each with strengths and limitations. Key-value stores such as Redis and Memcached are popular choices. Redis supports advanced data structures and persistence, while Memcached is lightweight and extremely fast for simple key-value lookups.
| Cache Store | Strengths | Limitations |
|---|---|---|
| Redis | Supports data structures, persistence, pub/sub, clustering | Higher memory footprint, slightly more complex setup |
| Memcached | Very fast, simple API, low memory overhead | No persistence, limited to simple key-value storage |
| CDN/Edge Cache | Reduces latency for globally distributed users, offloads server | Best suited for static content, requires integration with content pipeline |
Implementing a Cache: Practical Example
Implementing a cache in a Python web application can dramatically improve performance. Below is a pattern using Redis as a cache layer for database queries:
import redis
import psycopg2
# Initialize Redis client
cache = redis.Redis(host='localhost', port=6379, db=0)
# Database query function
def get_user_profile(user_id):
cache_key = f"user:{user_id}"
cached_data = cache.get(cache_key)
if cached_data:
return cached_data # Return cached result
# Query database if cache miss
conn = psycopg2.connect(dbname="app_db", user="user", password="pass", host="db_host")
cur = conn.cursor()
cur.execute("SELECT id, name, email FROM users WHERE id=%s", (user_id,))
result = cur.fetchone()
cur.close()
conn.close()
# Store result in cache with TTL of 60 seconds
cache.setex(cache_key, 60, result)
return result
This approach reduces repeated database hits for frequently requested user profiles, improving both latency and throughput.
Monitoring Cache Performance
Cache effectiveness should be continuously monitored. Key metrics include cache hit/miss ratios, eviction rates, and memory utilization. For instance, an online forum may observe that the top 10 most viewed threads account for 80% of read requests — tracking cache hits ensures that these popular threads are consistently served from memory.
Monitoring tools like Redis INFO, Prometheus exporters, or New Relic can provide real-time insights, enabling adjustments to TTLs, cache sizes, or eviction policies.
Trade-offs and Considerations
Caching introduces complexity and potential consistency issues. While it accelerates reads, stale data and memory overhead must be managed carefully. Decisions around TTLs, invalidation, and layered caching must align with application requirements.
- Pros: Reduced database load, improved response times, higher throughput, and better scalability.
- Cons: Risk of stale data, additional operational complexity, memory consumption, and potential cache consistency bugs.
Balancing these trade-offs is essential for building resilient and performant systems that scale effectively.
Conclusion
Caching is a crucial component of scalable system architecture, complementing a well-designed database by alleviating read pressure and improving user experience. By selecting appropriate caching strategies, stores, and invalidation mechanisms, systems can maintain low latency under heavy load. Continuous monitoring and careful trade-off management ensure that caching delivers maximum performance benefits without compromising data correctness. Next in the series: Scalability for Dummies - Part 4: Asynchronism.

Comments (0)