Understanding Caching in Scalable Systems
By Oleksandr Andrushchenko — Published on — Modified on
Caching is one of the most important patterns for building scalable systems. It reduces latency, lowers database load, absorbs traffic spikes, and helps systems serve repeated requests faster.
This article explains where caches are used, how different cache layers work, common update strategies, and the trade-offs engineers must consider when using caching in production systems.
Table of Contents
- Caching Overview
- Cache Layers
- Cache Granularity
- Cache Update Strategies
- Production Considerations
- Real-World Example
- Production Recommendations
- Conclusion
Caching Overview
What Caching Solves
Caching stores previously computed or fetched data so the system can reuse it instead of repeating expensive work. For example, if many users request the same product page, article, image, or dashboard result, the system can return a cached response instead of querying the database every time.
Caching improves page loading speed and reduces load on application servers and databases. In a scalable system, the dispatcher, web server, application, or dedicated cache layer may first check whether a request was already processed. If the result exists in cache, the system returns it immediately and avoids redundant processing.
Where Caches Live
Caches can live at multiple layers: the browser, operating system, CDN, reverse proxy, application server, dedicated cache service, database engine, or storage layer. Each layer solves a different problem. Browser and CDN caches reduce network latency. Application caches reduce repeated backend work. Database caches reduce disk access.
User
|
Browser Cache
|
CDN Cache
|
Web Server / Reverse Proxy
|
Application
|
Redis / Memcached
|
Database Cache
|
Disk / StorageCache Layers
Client Caching
Client caching stores data on the user’s device, such as in the browser, mobile app, operating system, or local storage. This is useful for static assets, images, fonts, JavaScript, CSS, user preferences, and data that does not need immediate freshness.
For example, a browser can cache a logo, stylesheet, or JavaScript bundle so the user does not download the same file on every page load. This reduces latency and saves bandwidth.
CDN Caching
CDN caching uses content delivery networks as distributed caches. A CDN stores content in edge locations close to users. This improves performance, reduces origin load, and can increase availability because cached content may still be served even if the origin is temporarily slow or unavailable.
User in Europe
|
European CDN Edge
|
Origin Server in US
|
DatabaseCDN caching is especially effective for public articles, images, videos, static assets, documentation, and cacheable API responses. The main trade-off is invalidation: once content is cached at the edge, updates must be handled with TTLs, versioned URLs, or explicit purge operations.
Web Server Caching
Web server caching happens at the reverse proxy or web server layer. Tools such as Varnish, Nginx, or caching proxies can serve static or dynamic responses without repeatedly calling the application server.
For example, a public landing page or blog article can be cached by a reverse proxy. The next request can be served directly from the web server cache, reducing application CPU usage and database queries.
Database Caching
Databases include internal caching mechanisms such as buffer pools, query plan caches, and page caches. These are usually optimized for general workloads, but tuning them for specific access patterns can improve performance further.
For example, PostgreSQL and MySQL keep frequently accessed data pages in memory. If a query repeatedly accesses the same indexed rows, the database may serve them from memory instead of disk. However, relying only on database caching may not be enough when the application repeatedly runs expensive queries.
Application Caching
Application caching uses in-memory stores such as Redis or Memcached between the application and persistent storage. Because data is stored in RAM, access is much faster than reading from disk-based databases.
Application caches commonly store sessions, permissions, user profiles, rendered pages, expensive query results, activity streams, counters, and frequently used objects. Redis also provides persistence options and advanced data structures such as lists, sets, sorted sets, streams, and hashes.
| Cache Layer | Best For | Main Risk |
|---|---|---|
| Client cache | Static assets and offline-friendly data | Hard to invalidate immediately |
| CDN cache | Public content and media | Stale edge content |
| Web server cache | Public pages and repeated responses | Incorrect caching of user-specific data |
| Database cache | Repeated database page and index reads | Limited by database memory |
| Application cache | Sessions, objects, query results, counters | Invalidation and consistency complexity |
Cache Granularity
Query-Level Caching
Query-level caching stores the result of a database query, often using a hash of the query and parameters as the cache key. This can reduce repeated database work when the same query is executed frequently.
Query:
SELECT * FROM products WHERE category = 'shoes' ORDER BY popularity LIMIT 20
Cache key:
query:products:category:shoes:sort:popularity:limit:20The main challenge is invalidation. If one product changes, the system must know which cached query results are affected. Complex queries, joins, filters, and pagination make this harder.
Object-Level Caching
Object-level caching stores application objects rather than raw query results. This is often easier to reason about because the cached key maps to a business entity, such as a user profile, product, session, activity stream, or permission set.
- User sessions
- User profiles
- Rendered web pages
- Activity streams
- User graph data
- Product details
- Feature flags
For example, instead of caching many different queries that include a user profile, the application can cache user:123:profile. When the user profile changes, that specific key can be invalidated or updated.
HTML-Level Caching
HTML-level caching stores a fully rendered page or page fragment. This can be extremely fast because the application does not need to recompute templates, database queries, or object composition.
This works well for public pages, articles, documentation, landing pages, and product pages with moderate freshness requirements. It is riskier for personalized pages because cached HTML may accidentally expose user-specific data if cache keys are not scoped correctly.
| Granularity | Example | Benefit | Trade-off |
|---|---|---|---|
| Query-level | Cached SQL query result | Quick database relief | Hard invalidation for complex queries |
| Object-level | user:123:profile |
Clear ownership and easier invalidation | May require object composition |
| HTML-level | Fully rendered article page | Very fast response | Risky for personalized content |
Cache Update Strategies
Cache-Aside
Cache-aside, also called lazy loading, means the application manages cache reads and writes. The application checks the cache first. If the entry is missing, it loads data from the database, stores it in cache, and returns the result.
- Check cache for entry.
- If missing, load from database.
- Add entry to cache.
- Return the result.
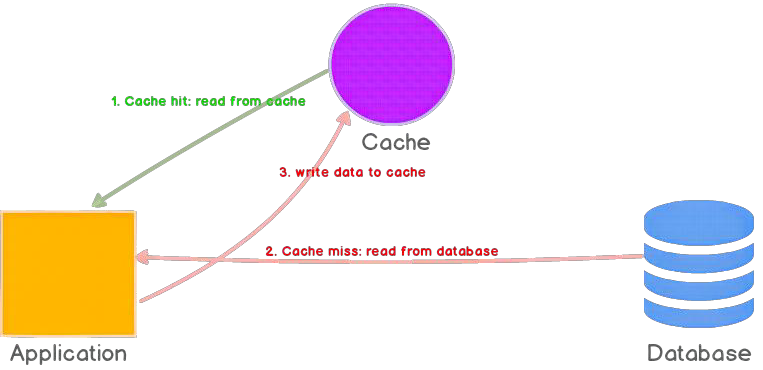
Cache-aside is widely used because it is simple and only requested data is cached. This reduces unnecessary memory usage. The trade-off is that each cache miss adds latency because the application must query the database before returning a response.
| Advantage | Disadvantage |
|---|---|
| Simple and flexible | Cache miss causes extra latency |
| Only requested data is cached | Data can become stale |
| Works with many databases and caches | New cache nodes start empty |
Write-Through
Write-through means writes go through the cache and are synchronously persisted to the database. The cache stays fresh because all updates pass through it.
- Application updates cache.
- Cache synchronously writes to database.
- Operation returns after persistence succeeds.
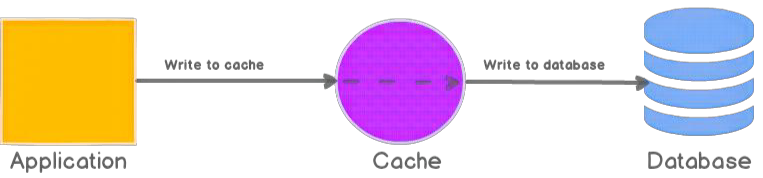
Write-through provides fast reads and better cache consistency, but writes are slower because the database must be updated before the operation completes. It can also write data that may never be read again.
Write-Behind
Write-behind, also called write-back, means the application writes to cache first, and the cache asynchronously updates the database later. This improves write performance from the application’s perspective because the write returns before the database is updated.
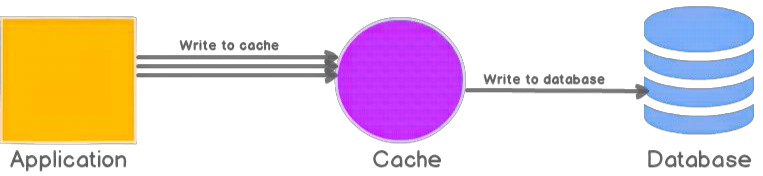
Write-behind is useful for high-write workloads, counters, logs, and data that can tolerate delayed persistence. The main risk is data loss if the cache fails before queued writes are flushed to the database.
- Improves write performance.
- Can batch many writes into fewer database operations.
- Introduces delayed persistence.
- Requires careful durability guarantees.
Read-Through
Read-through means the application reads data through the cache. If the data is not in the cache, the cache itself fetches it from the underlying source, stores it, and returns it to the application.
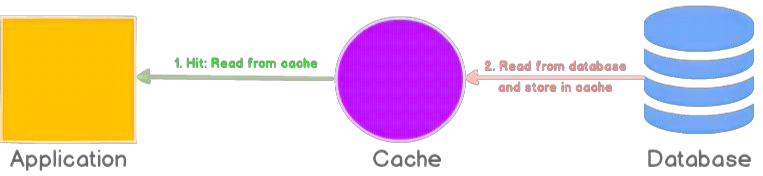
The goal is to simplify application logic. The application does not need to fetch from the database directly on a miss. This works well when reads are frequent and first-miss latency is acceptable.
Refresh-Ahead
Refresh-ahead automatically refreshes recently accessed entries before they expire. This reduces latency for future reads if predictions are accurate.
For example, if a homepage cache entry is accessed thousands of times per minute and expires every five minutes, refresh-ahead can update the entry before expiration so users do not experience a slow cache miss.
The main disadvantage is prediction cost. If the system refreshes data that users do not request again, it wastes compute and database capacity.
Strategy Comparison
| Strategy | Best For | Strength | Trade-off |
|---|---|---|---|
| Cache-aside | General application caching | Simple and flexible | Miss latency and stale data |
| Write-through | Data that should stay fresh in cache | Better consistency | Slower writes |
| Write-behind | High-write workloads and counters | Fast writes and batching | Risk of data loss before persistence |
| Read-through | Centralized read-loading logic | Simpler application code | Requires cache loader support |
| Refresh-ahead | Predictable hot keys | Avoids miss latency spikes | May refresh unused data |
Production Considerations
Cache Consistency
Maintaining consistency between cache and database requires careful invalidation. Cached data can become stale when the underlying database changes. Common solutions include TTLs, explicit invalidation, event-based invalidation, and versioned cache keys.
Product Updated
|
Database Updated
|
Publish ProductUpdated Event
|
Invalidate:
- product:123
- category:shoes:page:1
- homepage:featured-productsImportant trade-off: strict consistency is expensive. Use strict invalidation for critical data such as permissions, prices, inventory, and payment state. Use relaxed TTL-based caching for public content, feeds, recommendations, and analytics summaries.
Cache Capacity
Caches have limited memory. When capacity is reached, the cache must evict entries. Eviction policies such as LRU help keep recently accessed data in memory, but no policy is perfect.
| Policy | Meaning | Best For |
|---|---|---|
| LRU | Evicts least recently used entries | Workloads where recent access predicts future access |
| LFU | Evicts least frequently used entries | Workloads with stable hot keys |
| TTL | Expires entries after fixed time | Data with known freshness requirements |
| Random | Evicts random entries | Simple systems with low precision needs |
Autoscaling and File-Based Cache
File-based caching is usually discouraged in auto-scaling environments because files are local to a specific instance. When new instances are created, they start with empty caches. When instances are removed, their cached data disappears. This can create inconsistent performance and make debugging harder.
For distributed applications, use shared cache systems such as Redis, Memcached, CDN, or database-backed materialized views. Local in-memory cache can still be useful for very short-lived data, but it should not be the primary shared cache.
Real-World Example
Consider an e-commerce product page. Different parts of the page have different caching requirements. Images and descriptions can be cached for a long time. Prices and inventory need shorter TTLs or event-based invalidation. Recommendations can tolerate staleness and may be refreshed asynchronously.
User Request
|
CDN Cache
|
Application
|
+----------------------+----------------------+
| |
Redis Product Cache Inventory Service
| |
Database Direct / Short TTL Read| Data | Cache Layer | Recommended Strategy |
|---|---|---|
| Product image | CDN | Long TTL with versioned URL |
| Product description | CDN or Redis | TTL or event invalidation |
| Price | Application cache | Short TTL or event invalidation |
| Inventory | Database or short cache | Very short TTL or direct read |
| Recommendations | Redis | Refresh-ahead or cache-aside |
| Rendered page | CDN or reverse proxy | Only if personalized data is excluded |
Production Recommendations
- Start with cache-aside and TTLs. This is usually the simplest and safest first caching pattern.
- Cache read-heavy and expensive data first. Do not cache everything by default.
- Use object-level caching when possible. It is usually easier to invalidate than arbitrary query-level caching.
- Be careful with rendered HTML caching. Never cache personalized content without user-specific keys.
- Use shared caches in auto-scaling systems. Prefer Redis, Memcached, or CDN over local file cache.
- Design invalidation before caching critical data. Prices, permissions, inventory, and payment state need strict rules.
- Protect against cache stampedes. Use locks, request coalescing, TTL jitter, or refresh-ahead.
- Monitor hit ratio, miss latency, evictions, and memory usage. Caching without observability can hide serious problems.
- Document cache keys and TTLs. Future engineers need to understand what is cached and why.
Conclusion
Caching is a practical scalability pattern, but it is also a consistency and operations trade-off. It can dramatically improve performance, reduce database load, and help systems absorb traffic spikes, but it introduces complexity around invalidation, capacity, stale data, and failure behavior.
For most systems, start with simple cache-aside caching, clear TTLs, well-designed cache keys, and strong observability. Add write-through, write-behind, read-through, or refresh-ahead only when the workload justifies the added complexity.
Key takeaway: cache data that is expensive to fetch, frequently requested, and safe to serve slightly stale. For critical data, design invalidation and recovery before relying on cache.

Comments (0)