Scalability in Software System Design — A Practical Guide
By Oleksandr Andrushchenko — Published on — Modified on
What is scalability?
Scalability is the ability of a system to handle increased load — such as more users, data, or requests — without unacceptable performance degradation. It can be achieved in two main ways:
- Vertical scaling — adding more power to existing machines (CPU, RAM).
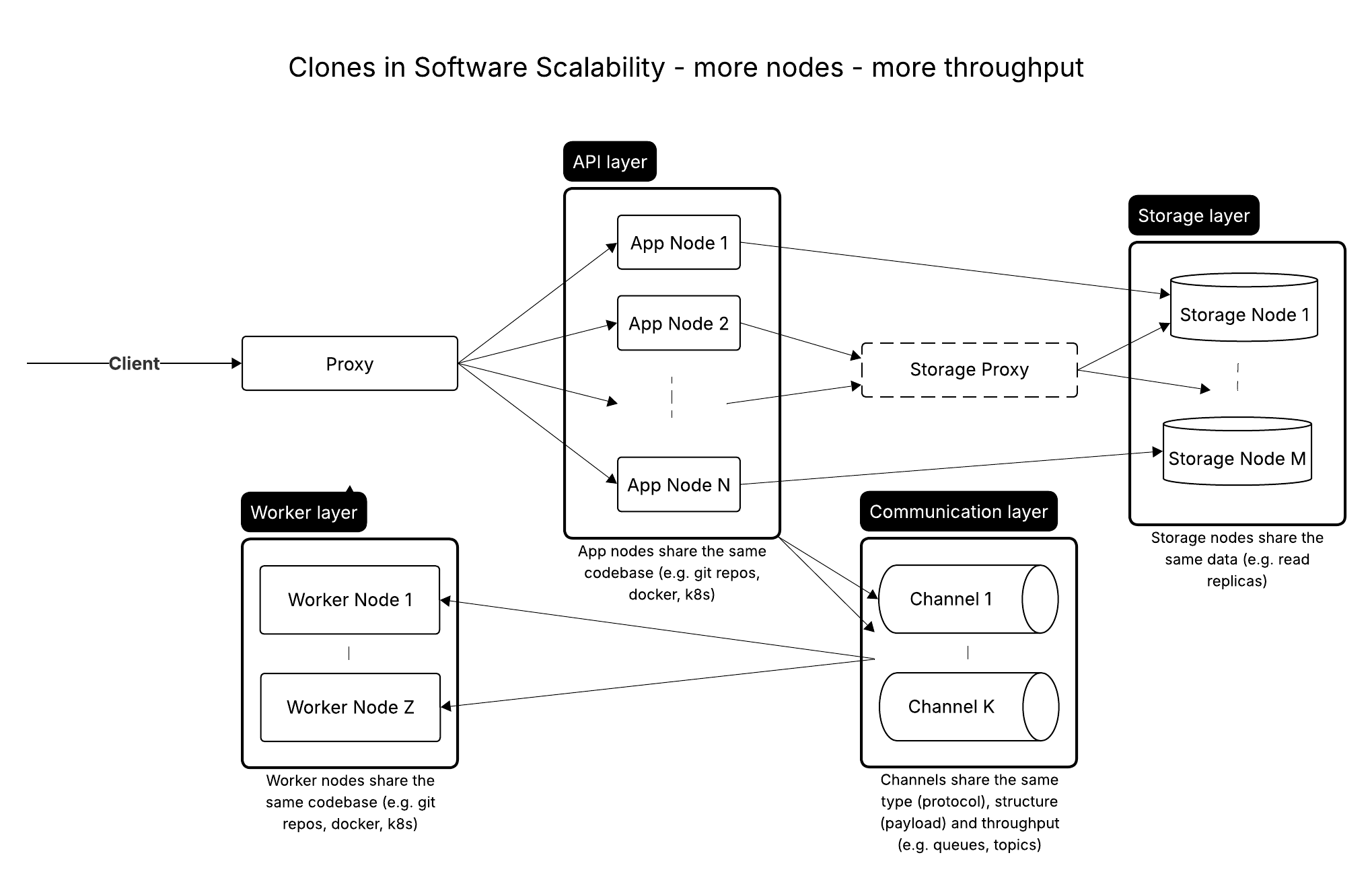
- Horizontal scaling — adding more machines and distributing load between them.
It also includes operational, cost, and development scalability — how the system, budget, and team scale with growth.
Core principles
- Loose coupling: components interact through clear interfaces or asynchronous messages.
- Stateless services: any instance can serve any request, enabling horizontal scaling.
- Partitioning (sharding): divide data into independent segments to reduce contention.
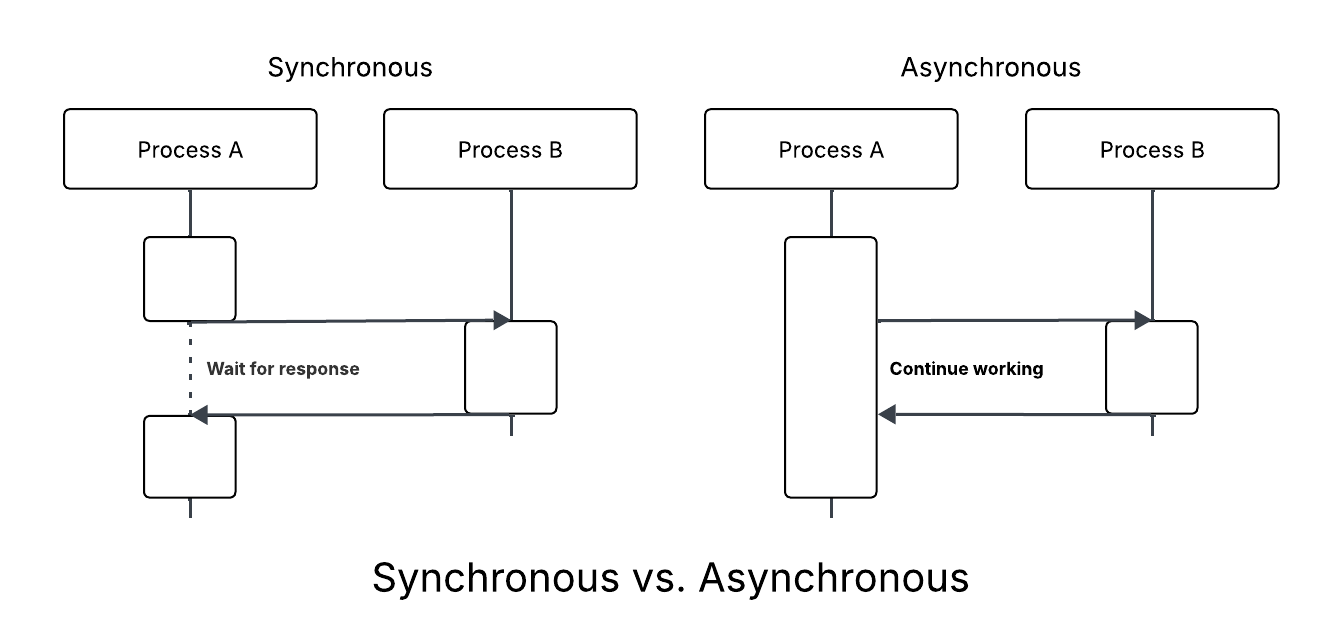
- Asynchronous processing: queues and events smooth traffic spikes and decouple components.
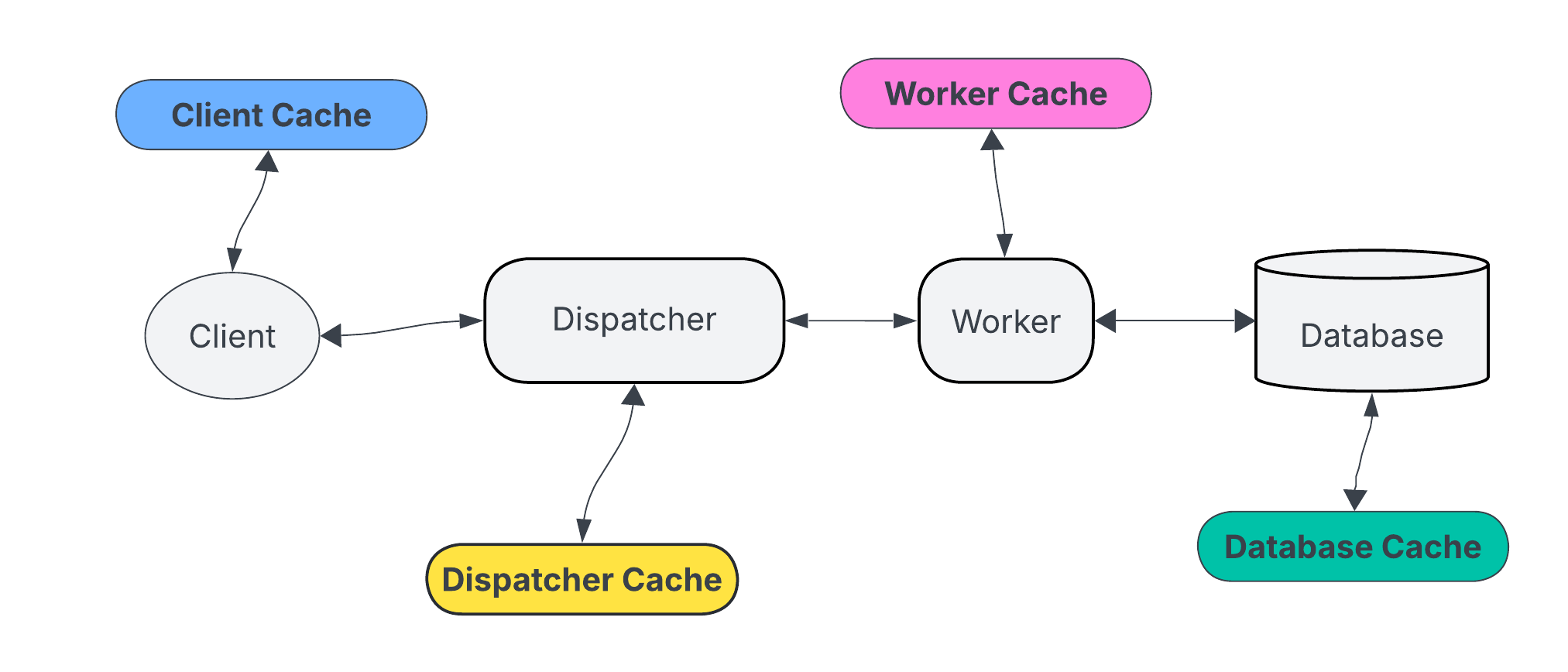
- Caching: use edge, application, and database-level caches to offload read pressure.
- Graceful degradation: design systems to stay functional even when parts fail.
Common architectural patterns
- Load balancing and autoscaling: distribute requests across healthy instances and adjust capacity based on metrics.

Load balancing and autoscaling - API Gateway and BFF: centralize routing, authentication, and rate limiting, with backends tailored per client type.
- CQRS and Event Sourcing: separate read and write paths for better scaling and resilience.
- Sharding: divide data by user, region, or time to parallelize storage and queries.
- Multi-tier caching: combine CDN, Redis/memcached, and in-app caches with proper invalidation strategies.
Trade-offs
- Consistency vs availability: strict consistency limits scalability; eventual consistency scales better for large systems.
- Complexity cost: more scalable systems are harder to operate — avoid premature scaling.
- Network vs compute: distributed systems introduce latency and failure risk; sometimes bigger machines are simpler.
- Observability: scaling without monitoring is dangerous — track metrics, logs, and traces.
Metrics and capacity planning
- Throughput (requests per second)
- Latency (p50, p90, p99)
- Error rates and timeouts
- Resource usage (CPU, memory, I/O)
- Queue length and lag
Example calculation:
// One instance handles 200 RPS at p99 < 200ms
Target: 20,000 RPS
instances = ceil(20000 / 200) = 100
Add redundancy (x1.5) → 150 instancesReliability patterns
- Bulkhead isolation: prevent one service from exhausting all resources.
- Circuit breaker and retries: avoid cascading failures.
- Back-pressure: slow producers when consumers lag.
- Rate limiting: protect shared resources from overload.
Operational practices
- Chaos testing: inject controlled failures to test resilience.
- Load testing: simulate real traffic patterns, not just steady load.
- Observability: use tracing, metrics, and logs for visibility.
- Automation: use autoscaling, monitoring alerts, and runbooks to reduce recovery time.
Scalability cheat sheet
| Problem | Solution | Notes |
|---|---|---|
| Read-heavy load | CDN, read replicas, caching | Set proper TTLs and invalidation |
| Write-heavy load | Sharding, batching, queues | Avoid cross-shard transactions |
| Spiky traffic | Autoscaling, buffering | Offload non-critical work asynchronously |
| Slow dependencies | Caching, retries, circuit breakers | Fail fast and isolate timeouts |
Practical checklist
- Identify bottlenecks and critical request paths.
- Measure baseline performance and capacity.
- Introduce caching strategically and measure its impact.
- Make services stateless to allow horizontal scaling.
- Use asynchronous queues for background or delayed work.
- Automate scaling and deployments.
- Design for failure with timeouts and fallbacks.
- Instrument everything and define SLAs/SLOs.
Final thoughts
Scalability isn’t a single feature — it’s a mindset and a set of design principles. Start small, measure, and scale incrementally. Favor simplicity until complexity becomes necessary, and always keep observability and automation at the core of your system design.
If you want a practical, beginner-friendly explanation of how horizontal scaling works, see Scalability for Dummies — Part 1: Clones.

Comments (0)