Database Transactions
By Oleksandr Andrushchenko — Published on — Modified on
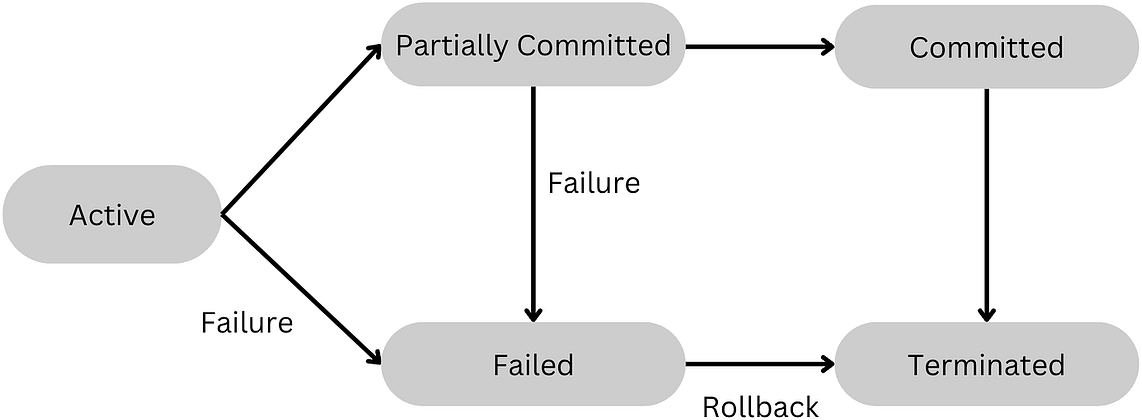
Database transactions are the foundation of correctness in systems that update important shared data, such as balances, inventory, orders, payments, permissions, and user state.
Table of Contents
- What Is a Database Transaction?
- ACID Properties
- Isolation Levels
- Locking and Deadlocks
- Transaction Boundaries
- Retries and Idempotency
- Distributed Transactions
- Observability
- Design Takeaways
What Is a Database Transaction?
A database transaction is a logical unit of work that groups multiple database operations into a single outcome. Either all important changes are committed, or all of them are rolled back.
This matters because many business operations are not single SQL statements. Creating an order, reserving inventory, recording payment, and updating user state may require multiple writes. If some of those writes succeed and others fail, the system can enter an invalid state.
Why Transactions Matter
Imagine a payment service that debits one account but fails before crediting another account. Without a transaction, the database may permanently store only half of the operation.
The same issue appears in many systems:
- An order is created, but inventory is not reserved.
- A user account is created, but the profile row is missing.
- A payment is marked successful, but the invoice remains unpaid.
- A subscription is activated, but billing setup fails.
Transactions protect systems from these partial-write states.
Transaction Example
A simple order transaction may look like this:
BEGIN;
INSERT INTO orders (id, user_id, status)
VALUES (1001, 10, 'CREATED');
UPDATE products
SET stock = stock - 1
WHERE id = 42
AND stock > 0;
INSERT INTO payments (order_id, status)
VALUES (1001, 'PENDING');
COMMIT;If something fails before COMMIT, the transaction can roll back and avoid storing an incomplete order flow.
ACID Properties
Transactions are usually explained through ACID: Atomicity, Consistency, Isolation, and Durability.
Atomicity
Atomicity means the transaction is all-or-nothing.
For example, user registration may require creating an account row and a profile row. If profile creation fails because of a constraint violation, the account row should not remain in the database.
BEGIN;
INSERT INTO users (id, email)
VALUES (1, 'user@example.com');
INSERT INTO profiles (user_id, display_name)
VALUES (1, 'Alex');
COMMIT;If the second insert fails, the first insert can be rolled back.
Consistency
Consistency means the database moves from one valid state to another valid state. Constraints such as foreign keys, unique indexes, check constraints, and application invariants help enforce this.
For example, a database can prevent duplicate emails with a unique constraint.
ALTER TABLE users
ADD CONSTRAINT unique_user_email UNIQUE (email);The application should still validate inputs, but database constraints are the last line of defense.
Isolation
Isolation controls how concurrent transactions see each other's changes.
For example, if one transaction is updating product inventory while another transaction is reading inventory, the database must decide what the second transaction is allowed to see.
Isolation is where many real-world transaction bugs happen. The transaction may be atomic, but concurrent reads and writes can still create race conditions if the isolation level or locking strategy is wrong.
Durability
Durability means that once a transaction commits, the data should survive crashes.
Relational databases commonly use write-ahead logging to make committed changes recoverable after a crash or power loss.
For example, after a bank transfer commits, the balances must not disappear because the server restarted.
Isolation Levels
Isolation levels control the trade-off between correctness, concurrency, and performance.
READ COMMITTED
READ COMMITTED usually means each statement sees only data that was committed before that statement started.
This is a common default isolation level and works well for many CRUD APIs and dashboards.
The trade-off is that two statements inside the same transaction may see different committed data if another transaction commits between them.
REPEATABLE READ
REPEATABLE READ gives a transaction a more stable view of data. If the transaction reads the same row twice, it should see the same version.
This is useful for financial summaries, reports, and workflows where a stable dataset matters during the transaction.
SERIALIZABLE
SERIALIZABLE is the strongest common isolation level. It attempts to make concurrent transactions behave as if they ran one after another.
This can prevent many anomalies, but it may also cause transaction aborts under high concurrency. Applications using SERIALIZABLE must be ready to retry failed transactions.
| Isolation Level | Prevents | Common Use Case | Trade-off |
|---|---|---|---|
| READ COMMITTED | Dirty reads | CRUD APIs and dashboards | Non-repeatable reads can happen |
| REPEATABLE READ | Dirty reads and non-repeatable reads | Financial summaries and stable reads | More contention or stale snapshot behavior |
| SERIALIZABLE | Most concurrency anomalies | Critical invariants | Transaction aborts and retries |

Locking and Deadlocks
How Locks Appear
Locks are the mechanism databases use to enforce isolation and protect data during concurrent access.
When a transaction updates a row, it usually acquires a lock on that row. If another transaction tries to update the same row, it may block until the first transaction commits or rolls back.
For example:
Transaction A:
UPDATE products SET stock = stock - 1 WHERE id = 42;
-- row is locked
Transaction B:
UPDATE products SET stock = stock - 1 WHERE id = 42;
-- waits until Transaction A commits or rolls backThis behavior is necessary, but it can reduce throughput if transactions hold locks too long.
Deadlock Example
A deadlock happens when two transactions wait on each other.
Transaction A:
locks row X
then waits for row Y
Transaction B:
locks row Y
then waits for row XNeither transaction can continue. Most databases detect the deadlock and abort one transaction. The application must then retry safely.
A common way to reduce deadlocks is to access shared resources in a consistent order.
Transaction Boundaries
Defining transaction boundaries is as important as choosing the isolation level.
Bad Boundary Example
A common anti-pattern is opening a transaction too early and keeping it open while the application performs slow work.
BEGIN
validate request
call external payment provider
update database
send email
COMMITThis is risky because the transaction may hold locks while waiting for external services. If the payment provider is slow, database resources remain locked longer than necessary.
Better Boundary Example
A better pattern is to keep the transaction focused on critical database mutations.
validate request outside transaction
calculate price outside transaction
BEGIN
create order
reserve inventory
create payment record
COMMIT
send email after commitFor example:
BEGIN;
SELECT stock
FROM products
WHERE id = 42
FOR UPDATE;
UPDATE products
SET stock = stock - 1
WHERE id = 42;
INSERT INTO orders (user_id, product_id, qty)
VALUES (10, 42, 1);
COMMIT;This keeps the critical section shorter and reduces lock contention.
For deeper details, see Database Locks and Transactions.
Retries and Idempotency
Why Retries Are Needed
Transactions can fail because of deadlocks, serialization conflicts, lock timeouts, network issues, or database failover.
Some of these errors are transient. Retrying can be correct, but only if the operation is safe to retry.
Idempotency Keys
Idempotency means the same operation can be performed multiple times without changing the result after the first successful attempt.
For example, a payment API should use an idempotency key so a retry does not charge the customer twice.
CREATE TABLE payment_requests (
idempotency_key TEXT PRIMARY KEY,
payment_id BIGINT NOT NULL,
created_at TIMESTAMPTZ NOT NULL DEFAULT NOW()
);If the same request is retried, the application can return the existing payment result instead of creating a duplicate charge.
- Retry only known transient errors.
- Use unique constraints or idempotency keys.
- Use exponential backoff to avoid retry storms.
- Log retry reasons and final outcomes.
Distributed Transactions
Two-Phase Commit
Distributed transactions try to coordinate one atomic commit across multiple databases or services.
Two-phase commit is one approach, but it increases coupling and can reduce availability during failures.
For example, if an order service and billing service must commit together, a coordinator may need to wait for both systems. If one service becomes unavailable, the whole operation may block.
Eventual Consistency Alternative
Many modern systems avoid distributed transactions across services. Instead, they use local transactions plus asynchronous events.
Order Service:
create order in local transaction
publish OrderCreated event
Billing Service:
consumes OrderCreated
creates payment record
Email Service:
consumes OrderCreated
sends confirmation emailIf something fails later, the system uses compensating actions such as refunding payment, releasing inventory, or marking an order as failed.
| Approach | Consistency | Availability | Operational Cost |
|---|---|---|---|
| Two-phase commit | Strong across participants | Lower under failure | High |
| Local transaction + events | Eventual across services | Higher | Moderate |
Observability
Transaction problems often do not appear during local development. They appear under production concurrency, where locks, slow queries, retries, and deadlocks interact.
Important metrics include:
- p95 and p99 transaction duration.
- Lock wait time.
- Deadlock count.
- Rollback rate.
- Retry rate.
- Slow queries inside transactions.
For example, if p99 transaction duration increases after a deployment, a new query may be holding locks longer than before. Without observability, this kind of issue is hard to diagnose.
Design Takeaways
- Use transactions for logically dependent writes.
- Keep transaction boundaries small and explicit.
- Use database constraints as a last line of defense.
- Choose isolation levels based on real business requirements.
- Understand that locks are part of transaction behavior under concurrency.
- Retry transient failures only when the operation is idempotent.
- Avoid distributed transactions unless the business truly requires them.
- Monitor transaction duration, lock waits, deadlocks, rollbacks, and retries.
The practical rule is simple:
Transactions protect the correctness of a unit of work, but good transaction design also requires careful boundaries, isolation choices, locking awareness, safe retries, and production observability.

Comments (0)