CAP Theorem in Practice (Structured Overview)
By Oleksandr Andrushchenko — Published on — Modified on
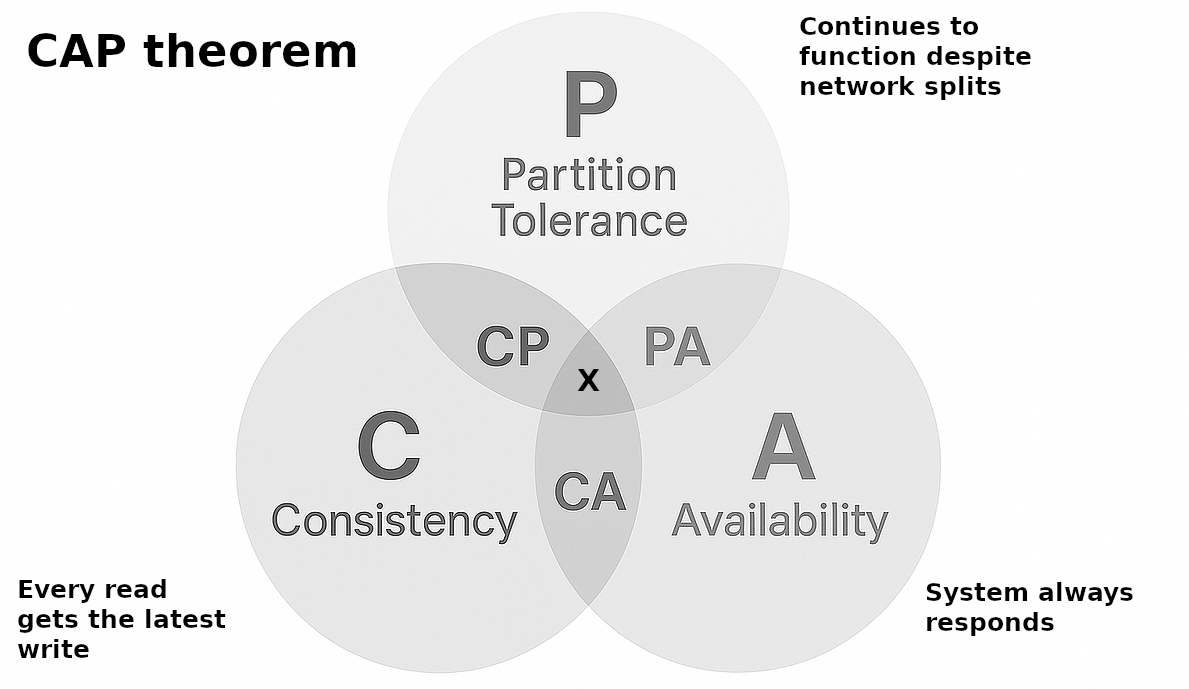
| # | System Type | Consistency | Availability | Partition Tolerance | Primary Behavior | Typical Use Case |
|---|---|---|---|---|---|---|
| 1 | CP | ✔ Strong | ✖ Reduced | ✔ Yes | Rejects requests when quorum is not available to preserve correctness | Payments, leader election, inventory reservation |
| 2 | AP | ✖ Eventual | ✔ High | ✔ Yes | Always serves requests even during partitions, may return stale data | Social feeds, caching systems, shopping carts |
| 3 | CA | ✔ Strong | ✔ High | ✖ No | Works only in non-distributed or tightly coupled environments | Single-node databases, embedded systems |
1. CP Systems (Consistency + Partition Tolerance, sacrifice Availability)
CP systems guarantee that all nodes maintain a consistent state even during partitions, but they reject or delay requests when coordination cannot be achieved. This is typically implemented using quorum-based replication or consensus protocols that require agreement before committing writes.
Examples
- Payment processing system (e.g., card authorization flow) where balance correctness is critical and double-spending must never occur even under network split.
- Distributed coordination system (e.g., leader election in a cluster) where only one active leader is allowed at any time, even if some nodes become unreachable due to partition.
- Stock exchange order matching engine where trade execution must remain globally consistent and partial execution is rejected if consensus cannot be guaranteed.
Trade-offs
| Property | Support | Behavior | Impact | Pros | Cons | Failure Mode |
|---|---|---|---|---|---|---|
| Consistency | ✔ | Strong consistency across replicas | No conflicting state | No data corruption, deterministic state | Requires coordination overhead | Safe but rigid state model |
| Availability | ✖ | Requests may be rejected under quorum loss | System blocks during partition | Protects correctness under failure | Reduced uptime, request failures | Timeouts / rejections |
| Partition tolerance | ✔ | Operates under network splits | Uses consensus protocols | Prevents split-brain issues | Higher latency due to coordination | Degraded throughput |
Code example
# CP system model:
# - Strong consistency is required across all replicas
# - Writes must be agreed upon by a quorum (majority)
# - If quorum is not available, the system rejects requests
# - This preserves correctness but sacrifices availability
replicas = ["node1", "node2", "node3", "node4", "node5"]
def write_with_quorum(key, value, available_nodes):
# Majority quorum is required to ensure consistency
quorum_size = 3
# ---------------------------------------------------------
# Partition detection behavior:
# If too few nodes are reachable, we DO NOT proceed
# because committing without quorum would break consistency
# ---------------------------------------------------------
if len(available_nodes) < quorum_size:
return "REJECTED: quorum not available (system prioritizes consistency)"
# ---------------------------------------------------------
# Commit phase:
# Only quorum nodes are allowed to accept the write
# This ensures all committed states are agreed upon
# ---------------------------------------------------------
committed_nodes = available_nodes[:quorum_size]
for node in committed_nodes:
print(f"{node} commits {key}={value}")
return "WRITE SUCCESS (consistent state guaranteed)"
# ---------------------------------------------------------
# Scenario: network partition happens
# Only 2 nodes are reachable instead of 3+
# ---------------------------------------------------------
available_nodes = ["node1", "node2"]
result = write_with_quorum("balance", 100, available_nodes)
print(result)
# ---------------------------------------------------------
# Key idea:
# CP systems NEVER risk inconsistent state.
# They prefer "no answer" over "wrong answer".
# ---------------------------------------------------------
2. AP Systems (Availability + Partition Tolerance, sacrifice Consistency)
AP systems guarantee that every request receives a response even during partitions, but allow temporary inconsistencies between nodes. This is typically implemented using local writes and asynchronous replication that later reconciles state.
Examples
- Social media timeline system (e.g., post feeds) where posts remain available during outages but different regions may temporarily see different ordering due to partitioning.
- Global shopping cart service where users can continue adding items during network disconnection, but carts may diverge across regions until synchronization happens.
- Content delivery / caching system (e.g., CDN edge caches) where stale content is acceptable in order to maintain high availability under partition conditions.
Trade-offs
| Property | Support | Behavior | Impact | Pros | Cons | Failure Mode |
|---|---|---|---|---|---|---|
| Consistency | ✖ | Eventual consistency only | Temporary divergence across nodes | High scalability, no coordination overhead | Stale or conflicting reads | Data drift until reconciliation |
| Availability | ✔ | Always responds | No request blocking | High uptime under all conditions | May serve outdated data | Always returns response |
| Partition tolerance | ✔ | System continues during splits | Independent regional writes | Resilient to network failures | Conflict resolution complexity | Eventual convergence delays |
Code example
# AP system model:
# - Each region can accept writes independently
# - No coordination required during partition
# - Data may diverge temporarily (eventual consistency)
region_a = {}
region_b = {}
def write(store, key, value):
# Local write only
# Always succeeds regardless of network state
store[key] = value
def sync(source, target):
# Simple reconciliation step
# In real systems this could be:
# - last-write-wins
# - vector clocks
# - CRDT merge
target.update(source)
# ---------------------------------------------------------
# Normal operation under network partition
# ---------------------------------------------------------
# Region A receives a write
write(region_a, "post", "Hello from A")
# Region B receives a different write at the same time
write(region_b, "post", "Hello from B")
# At this moment:
# - Both regions are AVAILABLE (system keeps working)
# - But data is NOT CONSISTENT across regions
print("Region A:", region_a)
print("Region B:", region_b)
# ---------------------------------------------------------
# After network heals (eventual consistency phase)
# ---------------------------------------------------------
sync(region_a, region_b)
# Now Region B is updated from Region A
# (In real systems, this is more complex and bidirectional)
print("After sync - Region B:", region_b)
# ---------------------------------------------------------
# Key idea:
# AP systems NEVER block writes during partition.
# They "prefer stale data over no data".
# ---------------------------------------------------------
3. CA Systems (Consistency + Availability, sacrifice Partition Tolerance)
CA systems provide strong consistency and high availability but assume no network partitions occur, which limits them to single-node or tightly coupled environments. They cannot operate correctly when distributed failures occur.
Examples
- Embedded database inside a mobile application where all data is strictly local and consistent, but there is no distributed communication layer at all.
- Single-node relational database used in early-stage applications where everything runs on one server instance, so consistency and availability are guaranteed only within that node, not across a cluster.
- Local configuration registry service inside a monolithic backend where state is shared only within one runtime environment, avoiding any need for partition handling or distributed coordination.
Trade-offs
| Property | Support | Behavior | Impact | Pros | Cons | Failure Mode |
|---|---|---|---|---|---|---|
| Consistency | ✔ | Strong consistency guaranteed | Always correct state | Simplifies reasoning, no conflicts | Not suitable for distributed systems | Stable in single-node scope |
| Availability | ✔ | Fast responses in healthy state | Simple execution model | Low latency, predictable behavior | Single point of failure risk | Works until infrastructure breaks |
| Partition tolerance | ✖ | No tolerance to network splits | Assumes no distributed failures | Simple architecture | Fails completely under partition | Total system outage |
Code example
class DB:
def __init__(self):
# Single-node in-memory storage
# No replication, no cluster, no network layer
self.store = {}
def write(self, key, value):
# Write is local and immediate
# Because there is only one node, consistency is trivial
self.store[key] = value
def read(self, key):
# Read is always from the same memory space
# No coordination or replication needed
return self.store.get(key)
# Create a single-node database instance
db = DB()
# Normal operation: system behaves with both consistency + availability
db.write("user", "alice")
print(db.read("user")) # always returns "alice"
# ---------------------------------------------------------
# Key idea of CA systems:
# They assume NO network partition exists.
# This means the system is NOT designed for distributed failure.
# ---------------------------------------------------------
# Simulated failure scenario:
# In real distributed systems, this would represent a network split
# or node isolation — but CA systems simply do not handle it.
raise Exception("Simulated partition: CA system has no recovery path")
Conclusions
CAP trade-offs are not theoretical labels but failure-time behavior models that define how a system reacts under network uncertainty. In practice, systems rarely fit a single category globally, and instead apply different CAP choices per subsystem depending on correctness and availability requirements. CP systems prioritize correctness at the cost of rejecting requests during failure conditions, AP systems prioritize continuous service with eventual reconciliation, and CA systems only remain valid in non-distributed or tightly controlled environments.
The real design decision is not “which CAP model is best”, but which failure mode is acceptable for each business capability. Payment processing tolerates unavailability over inconsistency, user-facing feeds tolerate inconsistency over downtime, and local systems avoid distribution entirely to preserve simplicity. The architectural outcome is typically a hybrid system where CP, AP, and CA coexist within the same platform, each enforcing different guarantees based on criticality and blast radius of failure.

Comments (0)