Availability patterns
By Oleksandr Andrushchenko — Published on — Modified on
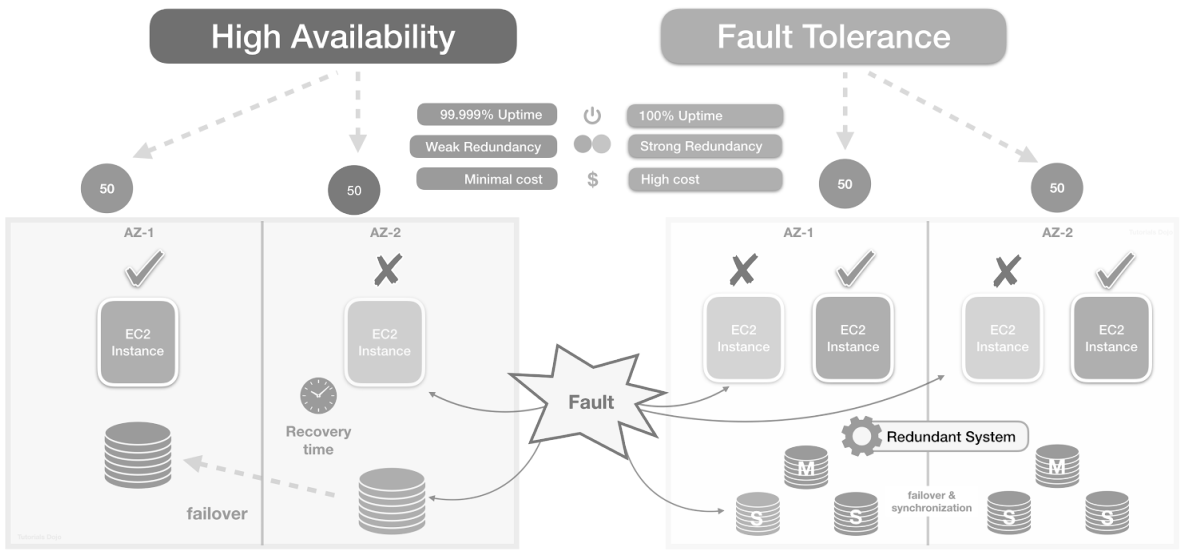
Availability patterns are system design techniques that keep applications operational during failures, overload, dependency issues, or partial outages.
Table of Contents
- What Is Availability?
- Redundancy and Replication
- Failover Strategies
- Load Balancing
- Graceful Degradation
- Circuit Breakers and Timeouts
- Monitoring and Recovery
- Choosing the Right Pattern
- Conclusion
What Is Availability?
Availability describes whether a system can continue serving users when something goes wrong. A highly available system does not assume that servers, databases, networks, or dependencies will always work. Instead, it is designed to survive failures and recover quickly.
For example, an e-commerce checkout API should continue accepting orders even if one application server crashes during a peak sale. A customer may not care which server failed. They only care whether checkout still works.
Why Availability Matters
Availability matters most when downtime directly affects revenue, trust, or critical business operations. Payment processing, authentication, healthcare systems, delivery platforms, and customer-facing APIs usually need stronger availability guarantees than internal reporting tools.
A SaaS analytics dashboard may tolerate a few minutes of delayed data during a database failover. A payment authorization service usually cannot. Different systems need different availability targets.
Availability Trade-offs
High availability is not free. It usually adds cost, infrastructure complexity, monitoring requirements, and sometimes consistency trade-offs.
For example, a marketing analytics pipeline can favor availability over strict consistency because delayed or approximate data does not block the business. A banking ledger cannot make the same trade-off because correctness is more important than serving stale data.
Redundancy and Replication
Redundancy
Redundancy means running extra components so that one failure does not stop the whole system.
A common example is deploying multiple stateless API servers behind a load balancer.
Client
│
▼
Load Balancer
├── API Server 1
├── API Server 2
└── API Server 3If one server fails, the load balancer can stop sending traffic to it and continue routing requests to healthy servers.
This pattern is simple but powerful. It works well for stateless services because any healthy instance can handle any request.
Replication
Replication applies the same idea to data. Instead of keeping only one copy of important data, the system keeps copies on multiple nodes or in multiple locations.
For example, a PostgreSQL primary database may handle writes while read replicas serve reporting queries or product catalog reads.
Application
│
├── Primary DB - writes
└── Read Replica - readsReplication improves availability, but it also introduces consistency questions. If replicas lag behind the primary, users may read slightly stale data.
| Aspect | Redundancy | Replication |
|---|---|---|
| Purpose | Keep service running when a component fails | Keep data accessible when a node fails |
| Common target | Application servers, workers, load balancers | Databases, caches, storage systems |
| Main benefit | Fault tolerance and capacity | Durability, read scaling, failover support |
| Main risk | More infrastructure to operate | Replica lag and consistency issues |
Failover Strategies
Failover is the process of moving traffic or responsibility from a failed component to a healthy one.
Automatic Failover
Automatic failover reduces recovery time because the system reacts without waiting for a human operator.
For example, a managed database service may promote a standby replica when the primary database fails.
Before failure:
Primary DB -> accepts writes
Standby DB -> waits
After failure:
Primary DB -> unavailable
Standby DB -> promoted to primaryThe advantage is faster recovery. The risk is false positives. If health checks are too aggressive, the system may fail over even when the primary is only temporarily slow.
Manual Failover
Manual failover gives engineers more control. It is useful when the cost of a wrong failover is high.
For example, a financial system may require an engineer to confirm database state before promoting a replica. This increases recovery time, but it can reduce the risk of data inconsistency.
Regional Failover
Regional failover moves traffic from one region to another during a large outage.
Normal:
Users -> us-east-1
Regional outage:
Users -> us-west-2This pattern improves resilience against regional cloud failures, but it is expensive and operationally complex. The system must handle data replication, DNS or traffic routing, deployment consistency, and failback.
Load Balancing
Load balancing improves availability by distributing traffic across multiple healthy backends. It prevents one server from becoming overloaded and allows unhealthy instances to be removed from rotation.
Health Checks
Health checks allow the load balancer to decide whether a backend should receive traffic.
A simple health check may call:
GET /healthA better health check verifies that the application can actually serve requests. However, health checks should not be too expensive. If every health check queries multiple databases and third-party APIs, the health check itself can become a source of load.
Routing Strategies
| Strategy | How It Helps Availability | Trade-off |
|---|---|---|
| Round-robin | Distributes traffic evenly | Does not understand backend capacity |
| Least connections | Sends traffic to less busy nodes | Requires more load balancer state |
| Health-check based | Removes unhealthy nodes from rotation | Bad health checks can cause false removals |
| Weighted routing | Gradually shifts traffic between versions or regions | Requires careful monitoring |
Weighted routing is especially useful during deployments. For example, a team can send 5% of traffic to a new version, monitor errors, then gradually increase traffic if everything looks healthy.
Graceful Degradation
Graceful degradation means preserving core functionality when non-critical parts of the system fail.
For example, an e-commerce site should still allow users to browse products and place orders even if the recommendation service is unavailable. Recommendations improve the experience, but checkout is more important.
Critical:
- Login
- Product page
- Cart
- Checkout
Optional:
- Recommendations
- Recently viewed items
- Personalized bannersA degraded system is not perfect, but it is still useful. This is much better than failing the entire request because one optional dependency is down.
Common graceful degradation techniques include:
- Return cached responses when a dependency fails.
- Hide optional widgets temporarily.
- Use default values instead of calling slow services.
- Queue non-critical work for later processing.
Circuit Breakers and Timeouts
Circuit breakers and timeouts prevent slow or failing dependencies from consuming all application resources.
A timeout limits how long the application waits. A circuit breaker stops calling a dependency after repeated failures.
import time
import requests
from typing import Any, Callable
class CircuitBreaker:
def __init__(
self,
failure_threshold: int = 3,
recovery_timeout: int = 10,
) -> None:
self.failure_threshold = failure_threshold
self.recovery_timeout = recovery_timeout
self.failure_count = 0
self.last_failure_timestamp: float | None = None
def _circuit_open(self) -> bool:
if self.failure_count < self.failure_threshold:
return False
if self.last_failure_timestamp is None:
return False
return (time.time() - self.last_failure_timestamp) < self.recovery_timeout
def call(self, operation: Callable[..., Any], *args, **kwargs) -> Any:
if self._circuit_open():
raise RuntimeError("Circuit breaker is open")
try:
result = operation(*args, **kwargs)
self.failure_count = 0
return result
except Exception:
self.failure_count += 1
self.last_failure_timestamp = time.time()
raise
def fetch_remote_data(url: str) -> dict:
response = requests.get(url, timeout=0.3)
response.raise_for_status()
return response.json()For example, if a pricing service starts timing out, the checkout API should not wait forever. It can fail fast, use cached pricing, or temporarily disable discounts depending on business rules.
Without timeouts and circuit breakers, one slow dependency can create a cascading failure.
Pricing service slow
▼
Checkout requests wait
▼
Application threads exhausted
▼
Healthy requests start failing
▼
Full outageMonitoring and Recovery
Availability patterns are only useful if the team can detect failures and recover from them. Monitoring should focus on user-visible symptoms, not only internal component health.
Important metrics include:
- Error rate: how many requests are failing.
- Latency: how long requests take.
- Saturation: whether CPU, memory, connections, queues, or workers are overloaded.
- MTTR: how quickly the system recovers.
- Availability: how often the service is usable.
For example, an alert saying “CPU is high” is useful, but an alert saying “checkout success rate dropped below 99%” is closer to what users actually experience.
Choosing the Right Pattern
Not every system needs every availability pattern. Over-engineering can make the system more expensive and harder to operate without providing meaningful business value.
| System Type | Reasonable Availability Approach |
|---|---|
| Internal reporting dashboard | Backups, basic monitoring, single-region deployment |
| Customer-facing API | Load balancing, redundancy, health checks, timeouts |
| Payment system | Strong failover plan, strict monitoring, careful consistency handling |
| Global SaaS platform | Multi-AZ deployment, regional strategy, graceful degradation |
The right pattern depends on business criticality, failure tolerance, data consistency requirements, and operational maturity.
Conclusion
Availability patterns help systems continue operating when components fail, dependencies slow down, or traffic spikes unexpectedly.
The most common patterns are redundancy, replication, failover, load balancing, graceful degradation, circuit breakers, timeouts, monitoring, and recovery planning.
The key is not to apply every pattern everywhere. The key is to understand which failure scenarios matter most for the business.
High availability is not about preventing every failure. It is about making sure failures do not become full system outages.

Comments (0)