Python Concurrency: Threads, Async, Await, and Event Loops
By Alex Snowgirl — Published on — Modified on
Modern applications rarely do only one thing at a time. They call APIs, query databases, read files, send notifications, process messages, and wait for external services. If every operation runs one after another, the application often spends most of its time waiting instead of doing useful work.
Python gives us two common ways to improve this: threads and async IO. Both can improve performance for IO-heavy workloads, but they work differently and have different trade-offs.
Table of Contents
- Concurrency Fundamentals
- Threads in Python
- Async Programming in Python
- Understanding the Event Loop
- CPU-Bound vs IO-Bound Workloads
- Threads vs Async
- Real-World Examples
- Common Mistakes
- Production Recommendations
- Conclusion
Concurrency Fundamentals
What Problem Are We Solving?
The main problem is waiting. A Python program may wait for an HTTP API response, database query, Redis call, file operation, message queue, email provider, payment provider, or network socket. During this waiting time, the CPU is often not doing much. The application is blocked, but not because it is performing heavy calculations. It is blocked because it is waiting for something outside the program.
Concurrency helps the program make progress on multiple tasks during the same period of time. It does not always mean multiple tasks are running on different CPU cores at the exact same moment. It means the program can use waiting time more efficiently.
Sequential Execution
The simplest way to write code is sequential execution. It is easy to read, but every operation waits for the previous operation to finish.
import requests
def fetch_user(user_id):
response = requests.get(f"https://api.example.com/users/{user_id}")
return response.json()
users = []
for user_id in [1, 2, 3]:
users.append(fetch_user(user_id))
print(users)If each API request takes one second, three requests take around three seconds. If the application needs to call 100 APIs, this becomes expensive. The CPU is not necessarily busy during this time; the program is mostly waiting for network responses.
Concurrency vs Parallelism
Concurrency means handling multiple tasks during the same time period. Parallelism means running multiple tasks at the same exact time, usually on multiple CPU cores. Threads and async are often used for concurrency. Multiprocessing or external worker systems are often used for CPU parallelism.
| Concept | Meaning | Example |
|---|---|---|
| Concurrency | Multiple tasks make progress during the same time period | Start several HTTP requests and handle responses as they arrive |
| Parallelism | Multiple tasks run at the same exact time | Process images on multiple CPU cores |
| Sequential execution | One task fully completes before the next starts | Call API A, then API B, then API C |
Sequential:
Task A ---- wait ---- done
Task B ---- wait ---- done
Task C ---- wait ---- done
Concurrent:
Task A ---- wait -------- done
Task B ---- wait ---- done
Task C ---- wait ---- doneThreads in Python
What Is a Thread?
A thread is a separate execution path inside the same process. You can think about a process as an application and threads as workers inside that application. Each thread can run a function independently.
Threads share the same memory space, which means they can access the same variables and objects. This can be useful, but it can also create bugs if multiple threads read and write the same data at the same time.
How Threading Works
When one thread is waiting for IO, another thread can continue working. For example, one thread can wait for an HTTP response while another thread starts another HTTP request. This makes threads useful for blocking IO operations, especially when using synchronous libraries such as requests, traditional database drivers, blocking SDKs, or SMTP clients.
Main Process
|
+----------+----------+----------+
| | |
Thread 1 Thread 2 Thread 3
API call DB query File readThread Example
import threading
import requests
def fetch_user(user_id):
response = requests.get(f"https://api.example.com/users/{user_id}")
print(response.json())
threads = []
for user_id in [1, 2, 3]:
thread = threading.Thread(target=fetch_user, args=(user_id,))
thread.start()
threads.append(thread)
for thread in threads:
thread.join()In this example, all three requests can start almost at the same time. When one thread waits for the network, another thread can continue. For IO-heavy work, this can significantly reduce total execution time.
Using ThreadPoolExecutor
In real code, manually creating and managing every thread can become messy. Python provides ThreadPoolExecutor, which is usually cleaner because it limits the number of active threads.
from concurrent.futures import ThreadPoolExecutor
import requests
def fetch_url(url):
response = requests.get(url, timeout=10)
return response.text
urls = [
"https://api.example.com/a",
"https://api.example.com/b",
"https://api.example.com/c",
]
with ThreadPoolExecutor(max_workers=10) as executor:
results = list(executor.map(fetch_url, urls))
print(results)A thread pool is important because creating too many threads can hurt performance and memory usage. Threads are useful, but they are not free.
Thread Pros and Cons
| Advantages | Disadvantages |
|---|---|
| Works well with blocking IO | Shared memory can create race conditions |
| Works with existing synchronous libraries | Debugging can be harder |
| Easy to add to older synchronous code | Too many threads consume memory |
| Useful for background jobs and worker-style processing | Thread scheduling is controlled by the operating system |
| Can improve IO-heavy workloads | CPU-heavy Python code is limited by the GIL in standard CPython |
The GIL, or Global Interpreter Lock, means that only one thread can execute Python bytecode at a time in standard CPython. This is why threads are usually a good fit for IO-bound work, but not the best choice for CPU-bound Python code.
Async Programming in Python
What Is Async?
Async programming is another way to handle waiting. Instead of creating many threads, async code usually uses one thread and switches between tasks when they are waiting. When one task waits for IO, it gives control back to the event loop so another task can run.
This makes async efficient for many network operations, such as web requests, sockets, queue consumers, async database calls, and websocket connections.
What Are async and await?
In Python, async defines a coroutine function. A coroutine is a function that can pause and resume later.
async def fetch_user(user_id):
...The await keyword pauses the current coroutine until an async operation finishes.
result = await some_async_operation()Important: await does not block the whole program. It only pauses the current coroutine and allows the event loop to run something else.
Async Example
import asyncio
import aiohttp
async def fetch_user(session, user_id):
async with session.get(f"https://api.example.com/users/{user_id}") as response:
return await response.json()
async def main():
async with aiohttp.ClientSession() as session:
tasks = [
fetch_user(session, 1),
fetch_user(session, 2),
fetch_user(session, 3),
]
```
users = await asyncio.gather(*tasks)
print(users)
```
asyncio.run(main())This code starts multiple HTTP requests concurrently without creating one thread per request. When one request waits for the network, the event loop can continue with another request.
Async Pros and Cons
| Advantages | Disadvantages |
|---|---|
| Efficient for many IO operations | Requires async-compatible libraries |
| Can handle many concurrent connections with fewer resources | Can make code harder to read at first |
| Strong fit for APIs, websockets, crawlers, and queue consumers | Blocking code inside async functions can destroy performance |
| Avoids many shared-memory problems common in threaded code | Error handling, cancellation, and timeouts can become more complex |
| Gives control over concurrency flow inside the application | Mixing sync and async code can be confusing |
Async is powerful, but it works best when the full stack supports async. If the HTTP client, database driver, or SDK is synchronous, async may not help much unless that blocking work is moved to a thread pool or separate worker.
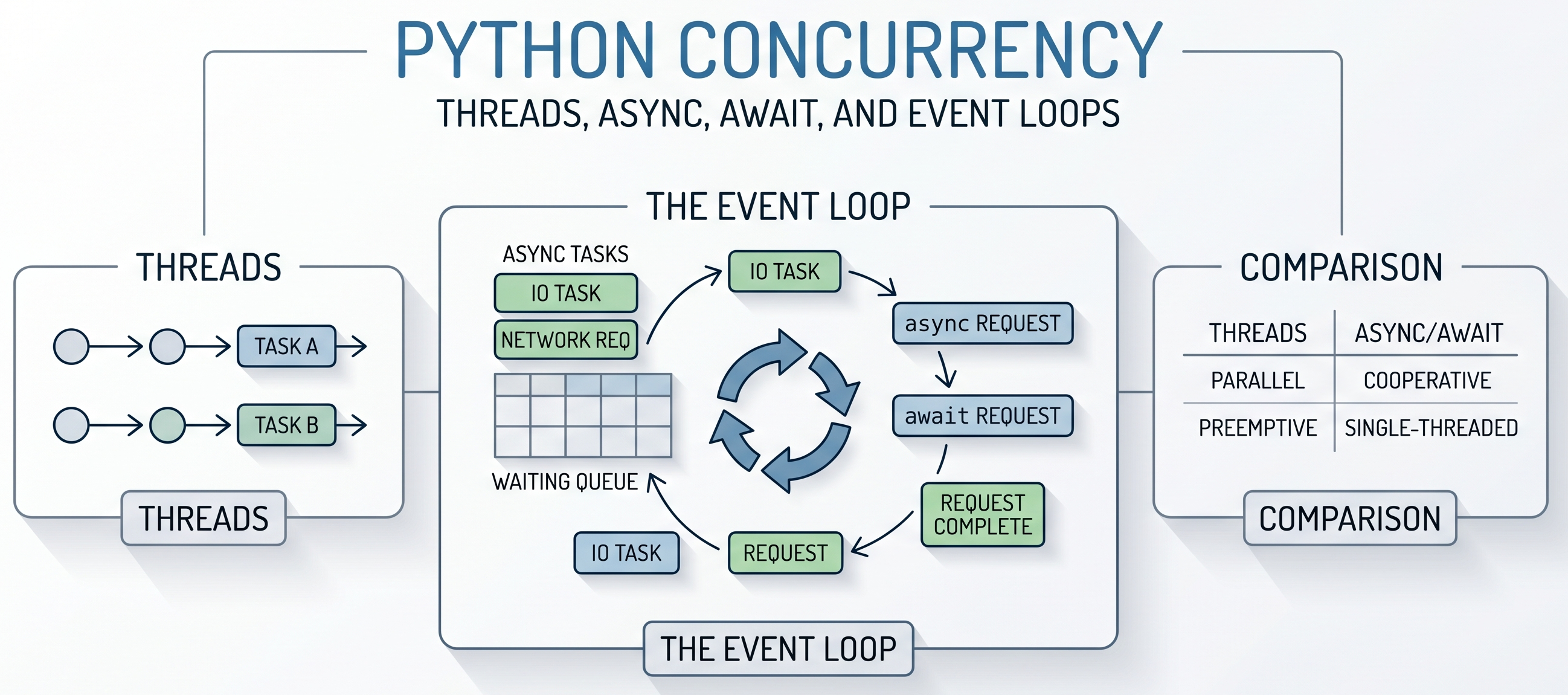
Understanding the Event Loop
How the Event Loop Works
The event loop is the core of async programming. It runs async tasks, pauses them when they wait, and resumes them when the result is ready.
Task A starts
Task A waits for API response
Event loop switches to Task B
Task B waits for database response
Event loop switches to Task C
Task A response is ready
Event loop resumes Task AThe event loop does not make slow operations faster by itself. It helps the program avoid wasting time while waiting.
What Happens During await?
When Python reaches an await, the current coroutine says: “I cannot continue right now. I am waiting for something.” Then the event loop can run another coroutine. Later, when the awaited operation completes, the event loop resumes the original coroutine from the same place.
async def get_data():
print("Before request")
result = await fetch_from_api()
print("After request")
return resultThe line after await runs only when fetch_from_api() is complete.
Why Async Is Efficient
Async is efficient because coroutines are lighter than threads. A system can usually handle many more coroutines than threads, especially when the tasks mostly wait for network IO.
- A websocket server with thousands of connected clients
- A crawler making many HTTP requests
- An API gateway calling multiple downstream services
- A queue consumer waiting for many external APIs
In these cases, async can provide high concurrency with relatively low overhead.
CPU-Bound vs IO-Bound Workloads
IO-Bound Work
IO-bound work spends most of its time waiting for input or output. Threads and async can both help with IO-bound workloads because they allow other work to continue while one operation waits.
- HTTP requests
- Database queries
- File reads and writes
- Redis calls
- Message queue operations
- Sending emails or SMS messages
CPU-Bound Work
CPU-bound work spends most of its time doing calculations. For CPU-heavy Python code, threads and async are usually not the best solution.
def calculate():
total = 0
for i in range(100_000_000):
total += i
return totalThis code does not spend most of its time waiting. It spends time using the CPU. For this kind of work, consider multiprocessing, separate worker services, native extensions, background job queues, or external compute systems.
Why Workload Type Matters
The most important question is not whether threads or async are faster. The better question is: is this workload waiting for IO, or is it using the CPU?
| Workload | Best Fit | Why |
|---|---|---|
| Many blocking HTTP calls | Threads | Works with synchronous libraries |
| Many async HTTP calls | Async | Lower overhead for many waiting tasks |
| Heavy calculation | Multiprocessing or workers | Needs CPU parallelism |
| Database calls with sync driver | Threads | Driver blocks the current thread |
| Database calls with async driver | Async | Event loop can switch while waiting |
Threads vs Async
Feature Comparison
| Feature | Threads | Async IO |
|---|---|---|
| Execution model | Multiple threads inside one process | Coroutines managed by an event loop |
| Best for | Blocking IO | High-volume non-blocking IO |
| Library support | Works with synchronous libraries | Requires async-compatible libraries |
| Memory usage | Higher when many threads are created | Usually lower for many concurrent tasks |
| Debugging | Can be hard because of shared state | Can be hard because of async flow and cancellation |
| CPU-heavy work | Limited by the GIL in CPython | Not a good fit |
| Typical use case | Run blocking tasks concurrently | Handle many network operations efficiently |
Performance Considerations
Threads can improve performance when tasks spend time waiting, but each thread has overhead. If too many threads are created, the operating system must manage them, schedule them, and allocate memory for them.
Async has lower overhead for large numbers of waiting tasks, but only if the code is truly non-blocking. If blocking code runs inside async functions, the event loop can be blocked, and the whole application can become slow.
Decision Table
| Situation | Recommended Approach |
|---|---|
| Existing synchronous code with blocking libraries | Threads or ThreadPoolExecutor |
| New high-concurrency API using async libraries | Async IO |
| Websocket server with many connections | Async IO |
| Moderate number of blocking background jobs | Threads |
| Heavy CPU computation | Multiprocessing, workers, or external compute |
| Simple script with small workload | Sequential code may be enough |
Real-World Examples
Calling Multiple APIs
Calling multiple external APIs is a classic IO-bound problem. With threads, you can keep using a synchronous HTTP client.
from concurrent.futures import ThreadPoolExecutor
import requests
def fetch_url(url):
response = requests.get(url, timeout=10)
return response.json()
urls = [
"https://api.example.com/users/1",
"https://api.example.com/users/2",
"https://api.example.com/users/3",
]
with ThreadPoolExecutor(max_workers=5) as executor:
results = list(executor.map(fetch_url, urls))
print(results)With async, you can use an async HTTP client.
import asyncio
import httpx
async def fetch_url(client, url):
response = await client.get(url, timeout=10)
return response.json()
async def main():
urls = [
"https://api.example.com/users/1",
"https://api.example.com/users/2",
"https://api.example.com/users/3",
]
async with httpx.AsyncClient() as client:
tasks = [fetch_url(client, url) for url in urls]
results = await asyncio.gather(*tasks)
print(results)
asyncio.run(main())Both approaches can work. The better choice depends on the rest of the application and the libraries already used.
FastAPI Web Server
Async is a strong fit for modern web APIs, especially when routes call other network services.
from fastapi import FastAPI
import httpx
app = FastAPI()
@app.get("/users/{user_id}")
async def get_user(user_id: int):
async with httpx.AsyncClient() as client:
response = await client.get(f"https://api.example.com/users/{user_id}")
return response.json()While this route waits for the external API, the server can continue handling other requests. But the benefit depends on using async-compatible libraries. If the route calls blocking code directly, it can block the event loop.
Background Job Processing
Threads are often useful for background workers when the job uses blocking libraries.
from concurrent.futures import ThreadPoolExecutor
def send_email(email):
# Blocking SMTP or provider API call
print(f"Sending email to {email}")
emails = [
"user1@example.com",
"user2@example.com",
"user3@example.com",
]
with ThreadPoolExecutor(max_workers=5) as executor:
executor.map(send_email, emails)This approach is simple and practical when each job spends most of its time waiting for an external service.
Database Operations
Database calls are usually IO-bound. Threads can help when using synchronous database drivers. Async can help when using async database drivers.
async def get_user(pool, user_id):
async with pool.acquire() as connection:
row = await connection.fetchrow(
"SELECT id, name, email FROM users WHERE id = $1",
user_id,
)
return dict(row)Concurrency does not remove database limits. If the application sends too many queries at the same time, it can overload the database. Connection pools, timeouts, and backpressure are still important.
Web Scraping
Web scraping often involves many HTTP requests, so async can be a good fit. However, concurrency should be controlled to avoid overloading remote servers or getting blocked.
import asyncio
import httpx
async def fetch_page(client, url):
response = await client.get(url)
return response.text
async def main():
urls = [
"https://example.com/page-1",
"https://example.com/page-2",
"https://example.com/page-3",
]
async with httpx.AsyncClient() as client:
pages = await asyncio.gather(
*(fetch_page(client, url) for url in urls)
)
print(len(pages))
asyncio.run(main())Common Mistakes
Using Blocking Code Inside Async Functions
This is one of the most common mistakes. The function is marked as async, but requests.get() is still blocking.
import requests
async def bad_example():
response = requests.get("https://api.example.com")
return response.json()A better version uses an async HTTP client.
import httpx
async def good_example():
async with httpx.AsyncClient() as client:
response = await client.get("https://api.example.com")
return response.json()Thinking Async Means Parallel
Async does not mean multiple tasks are running on multiple CPU cores at the same time. Async means tasks can pause while waiting and let other tasks run. This is concurrency, not necessarily parallelism.
Creating Too Many Threads
Threads are useful, but they are not free. Creating thousands of threads can increase memory usage and scheduling overhead. Use thread pools and reasonable limits.
Using Async Everywhere Without a Reason
Async adds complexity. If the code is simple, sequential, and fast enough, async may not be needed. Good engineering is not about using the most advanced tool. It is about using the right tool for the problem.
Production Recommendations
- Start by identifying the workload type. IO-bound and CPU-bound problems need different solutions.
- Use threads for blocking IO. This is often the easiest improvement for existing synchronous code.
- Use async for high-concurrency IO. It works well when the full stack supports async libraries.
- Do not block the event loop. Avoid synchronous HTTP clients, database drivers, or SDK calls inside async functions.
- Limit concurrency. Use thread pool limits, connection pools, semaphores, and rate limits.
- Use timeouts everywhere. Network calls without timeouts can hang workers or coroutines.
- Use multiprocessing or workers for CPU-heavy tasks. Threads and async are not the right primary tools for heavy CPU work.
- Monitor queue lag, latency, error rates, and resource usage. Concurrency can hide overload until it becomes severe.
Conclusion
Threads and async solve a similar problem: they help applications do useful work instead of wasting time while waiting.
Threads are usually easier to add to existing synchronous code. They are a good fit for blocking IO and moderate concurrency. Async is more efficient for large numbers of concurrent IO operations, but it requires async-compatible libraries and careful code structure.
Key takeaway: do not ask only which one is faster. Ask what kind of work your application does. If it waits for APIs, databases, files, queues, or sockets, threads or async can help. If it performs heavy CPU calculations, use multiprocessing, workers, native extensions, or external compute.
Concurrency is not magic. It is a tool for using waiting time better.
Comments (0)